Understanding the Layers of AI Visualization in the Age of LLMs

Artificial intelligence (AI) visualization refers to the ability to understand, monitor, and evaluate AI systems by tracking their unique metrics—such as token usage, response quality, latency, and model driving. Unlike traditional software, large-scale linguistic models (LLMs) and other generative AI applications are inherently scalable. They don’t follow established, obvious paths, which makes their decisions difficult to track and reason about. This “black box” behavior creates reliability challenges, especially in high-end or critical manufacturing environments.
AI systems are no longer test demos—they are production software. And like any production plan, they need visibility. Traditional software engineering has long relied on logging, metrics, and distributed monitoring to understand system behavior at scale. As LLM-enabled applications move into real-world user workflows, the same discipline becomes essential. To use these systems reliably, teams need visibility into what’s happening at each step of the AI pipeline, from inputs and model responses to downstream actions and failures.

Now let’s understand the different layers of AI visualization with the help of an example.
Think of an AI re-evaluation process as a sequence of steps rather than a single black box. A recruiter uploads a resume, the system processes it through multiple sections, and finally returns a shortlist score or recommendation. Each step takes time, has associated costs, and may fail separately. Just looking at the last recommendation may not reveal the whole picture, as fine details may be missed.
This is why leads and spans are important.
Clues
Tracking represents the complete lifecycle of a single retransmission—from the time the file is uploaded to the point where the endpoint is returned. You can think of it as a single continuous timeline that captures everything that happens in that application. All traces have a unique Trace ID, which includes all related activities.
Spanners
Each major activity within a pipeline is considered a span. These spaces are placed within the track and represent specific pieces of work.
Here’s what those spans look like in this system:
Load the Span
The resume is uploaded by the employer. This session records the time stamp, file size, format, and basic metadata. This is where the trail begins.
Parsing Span
The document is converted into structured text. This span captures time and analysis errors. If the reboot fails to parse properly or formatting breaks, the problem arises here.
Spanish Extraction Feature
The analyzed text is analyzed to extract skills, information, and keywords. This span tracks latency and average results. Poor output quality is evident in this category.
Scoring goals
The extracted features are transferred to the scoring model. This model logs span delays, confidence scores, and any regression logic. This is usually the most computer intensive step.
Decision Time
The system produces a final recommendation (shortlisting, rejection, or revision). This span records the output resolution and response time.
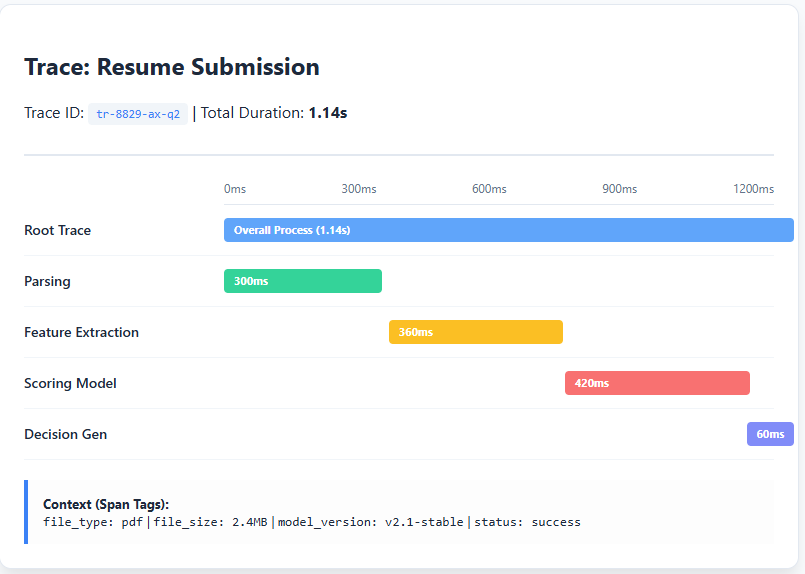
Why Span Level Visualization is Important
Without span-level tracking, all you know is that the last recommendation was wrong—you can’t see if the resume failed to parse correctly, key skills were missed during extraction, or the scoring model behaved unexpectedly. Span-level visualization makes each of these failure modes obvious and correctable.
It also reveals where time and money are being spent, such as whether analysis delays are increasing or scoring is controlling computing costs. Over time, as startup formats evolve, new capabilities emerge, and job requirements change, AI systems can quietly degrade. Extensive independent monitoring allows teams to spot these drifts early and fix specific components without retraining or redesigning the entire system.
AI visualization offers three key benefits: cost control, compliance, and continuous model improvement. By gaining visibility into how AI components are interacting with the broader system, teams can quickly identify wasted resources—for example, in a re-evaluation bot, visualization may reveal that document parsing is not easy while candidate scoring is taking up a lot of computing power, allowing teams to optimize or scale resources accordingly.
Visualization tools also facilitate compliance by automatically collecting and storing telemetry such as inputs, decisions, and time stamps; for the resume bot, this makes it easy to check how the candidate’s data has been processed and demonstrate adherence to data protection and recruitment regulations.
Finally, rich telemetry captured at each step helps model engineers maintain integrity over time by detecting drift as resume formats and skills change, identifying which factors actually influence decisions, and uncovering potential bias or fairness issues before they become systemic problems.
Langfuse is an open source LLMOps and visualization tool that has grown rapidly since its launch in June 2023. It is model- and framework-agnostic, supports self-hosting, and easily integrates with tools like OpenTelemetry, LangChain, and the OpenAI SDK.
At a high level, Langfuse gives teams end-to-end visibility into their AI systems. It offers LLM call tracking, tools to evaluate model results using human or AI feedback, fast centralized management, and performance and cost monitoring dashboards. Because it works across different models and frameworks, it can be added to existing AI workflows with minimal friction.
Arize is a ML and LLM visualization platform that helps teams monitor, test, and analyze models in production. It supports traditional ML models and LLM-based systems, and integrates well with tools like LangChain, LlamaIndex, and OpenAI-based agents, making it suitable for modern AI pipelines.
Phoenix, Arize’s open source offering (licensed under ELv2), focuses on LLM visibility. It includes built-in hallucination detection, detailed tracking using OpenTelemetry standards, and behavioral model testing and debugging tools. Phoenix is designed for teams that want transparent, self-contained visibility of LLM applications without relying on managed services.
TruLens is a visual tool that focuses on the quality assessment of LLM answers. Instead of emphasizing infrastructure-level metrics, TruLens attaches feedback tasks to each LLM call and evaluates the feedback generated after it is generated. These feedback functions behave like models themselves, scoring or evaluating factors such as appropriateness, relevance, or alignment with expectations.
TruLens is Python-only and available as free and open source software under the MIT License, making it easy to adopt for teams looking for lightweight, responsive testing without the full LLMOps platform.

I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I am very interested in Data Science, especially Neural Networks and its application in various fields.



