Google AI Releases TranslateGemma: A New Family of Open Source Translation Models Built on Gemma 3 Based on 55 Languages

Google AI has released TranslateGemma, a collection of open source machine translation models built on Gemma 3 and targeting 55 languages. The family comes in parameter sizes 4B, 12B and 27B. It is designed to run on all devices from mobile and peripherals to laptops and a single instance of the H100 GPU or TPU in the cloud.
TranslateGemma is not a unique architecture. It is a special Gemma 3 translation with a two-stage post training pipeline. (1) good supervision configuration in the corresponding large company. (2) Reinforcement learning that improves the quality of translation through the combination of multiple signal rewards. The goal is to push the quality of the translation while maintaining a standard order following Gemma 3 behavior.
Supervised fine tuning of synthetic and human analog data
The supervised fine-tuning stage begins at Gemma 3 public checkpoints 4B, 12B and 27B. The research team uses complementary data that includes human interpretation and high-quality artificial interpretation produced by Gemini models.
Synthetic data is generated from monolingual sources through a multi-step process. The pipeline selects candidate sentences and short documents, feeds them to Gemini 2.5 Flash, and filters the output with MetricX 24 QE to retain only examples that show clear quality gains. This is used in all WMT24 language pairs plus plus plus 30 more language pairs.
Low resource languages receive similar human-generated data from the SMOL and GATITOS datasets. SMOL covers 123 languages and GATITOS covers 170 languages. This improves the coverage of documents and language families represented under the same publicly available web database.
The final supervised fine-tuning mix also maintains the standard 30 percent instructions following the data from the original mix of Gemma 3. This is important. Without it, the model will specialize in pure translation and lose the usual behaviors of LLM such as following instructions or simple thinking in context.
Training uses Kauldron SFT (Supervised Fine Tuning) tools with AdaFactor optimizer. The learning rate is 0.0001 with a batch size of 64 for 200000 steps. All model parameters are updated without embedding tokens, frozen. Freeze embedding helps preserve the representational quality of languages and scripts that do not appear in supervised fine-tuning data.
Enhancing learning through a translation-focused award combination
After supervised optimization, TranslateGemma applies a reinforcement learning phase over a mixture of similar translation data. Reinforcement learning targets using several reward models.
The prize pool includes:
- MetricX 24 XXL QE, a learned regression metric that is very similar to MQM scores and is used here in quality measurement mode without a reference.
- Gemma AutoMQM QE, fine-tuned span level error prediction from Gemma 3 27B IT on MQM labeled data. Generates token level rewards based on error type and severity.
- ChrF, a character n gram overlap metric that compares model output to synthetic references and is rescaled to match other metrics.
- Naturalness Autorater that uses a policy model as an LLM judge and generates span-level penalties for segments that do not sound like native text.
- A generalist award model from a Gemma 3 post-training setting that keeps thinking and teaching skills intact.
TranslateGemma uses reinforcement learning algorithms that combine sequence level rewards with token level rewards. Span level rewards from AutoMQM and Naturalness Autorater attach directly to affected tokens. These token benefits are added to the sequence programs calculated from the reward you will go to and the collection is normalized. This improves credit allocation compared to rigorous sequential level learning.
Benchmark results on WMT24++
TranslateGemma is tested on WMT24++ benchmark using MetricX 24 and Comet22. MetricX is better down and consistent with MQM’s error statistics. Comet22 is the best and measures adequacy and fluency.
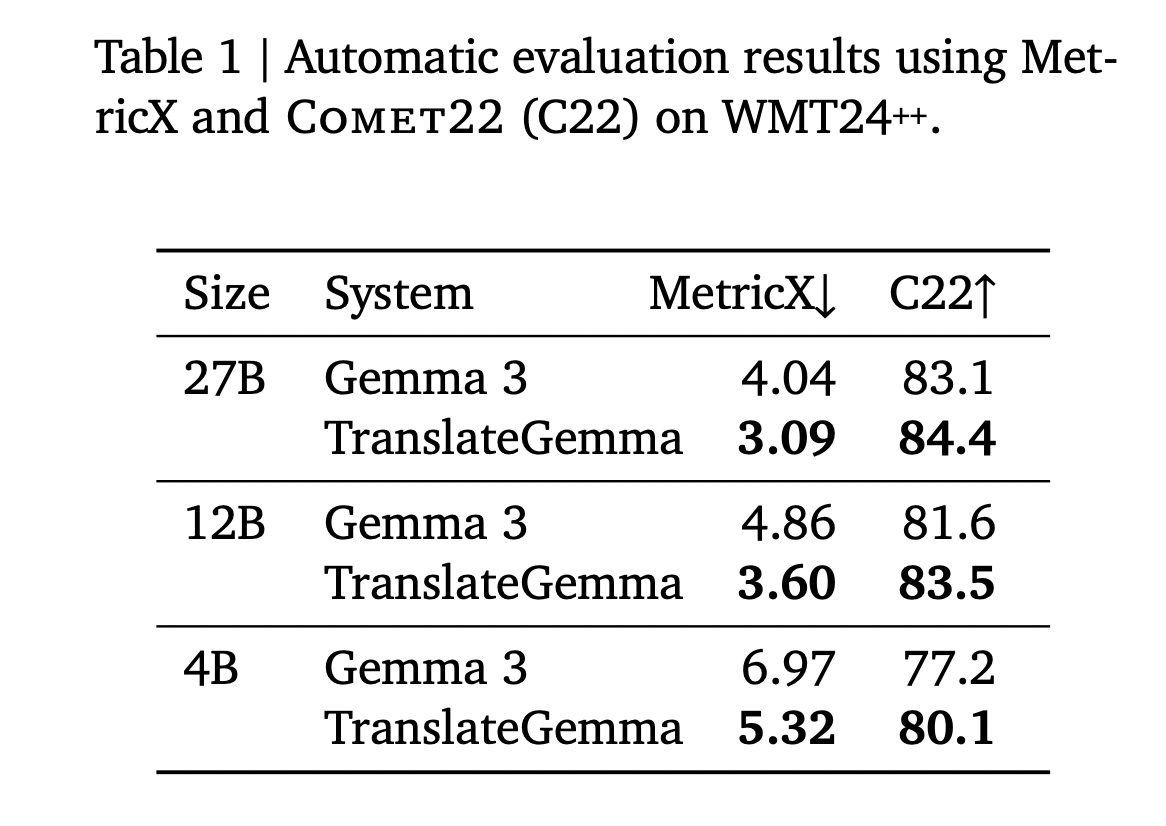
The above table from a research paper summarizes the results of an English-focused test of over 55 language pairs.
- 27B: Gemma 3 base has MetricX 4.04 and Comet22 83.1. TranslateGemma 27B reaches MetricX 3.09 and Comet22 84.4.
- 12B: Gemma 3 base has MetricX 4.86 and Comet22 81.6. TranslateGemma 12B reaches MetricX 3.60 and Comet22 83.5.
- 4B: Gemma 3 base has MetricX 6.97 and Comet22 77.2. TranslateGemma 4B reaches MetricX 5.32 and Comet22 80.1.
The main pattern is that TranslateGemma improves the quality of every model size. At the same time, the scale of the models interacts with the specialization. The 12B TranslateGemma model outperforms the base 27B Gemma 3. The 4B TranslateGemma model achieves the same quality as the base 12B Gemma 3. This means that the special translation model can replace the main base model in many machine translation tasks.
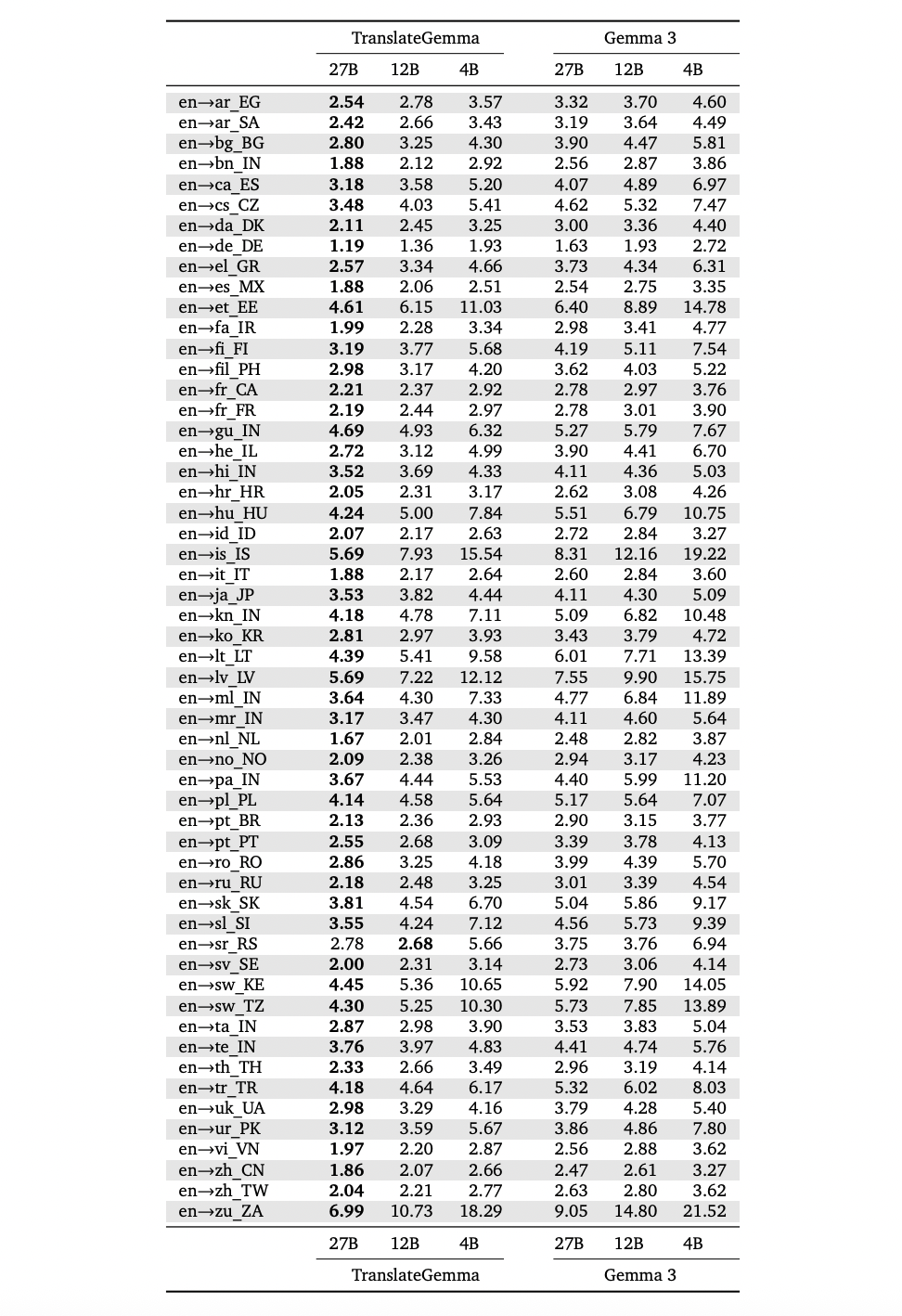
The language level breakdown in the appendix table above from the research paper shows that these benefits appear in all 55 languages. For example, MetricX improves from 1.63 to 1.19 for English to German, 2.54 to 1.88 for English to Spanish, 3.90 to 2.72 for English to Hebrew, and 5.92 to 4.45 for English to Swahili. The improvement is also big in difficult cases like English to Lithuanian, English to Estonian and English to Icelandic.
Human testing on WMT25 by MQM confirms this trend. TranslateGemma 27B tends to produce lower MQM scores, i.e. fewer weighted errors, than Gemma 3 27B, with particularly strong advantages for low-level directions such as English to Marathi, English to Swahili and Czech to Ukrainian. There are two notable exceptions. In German as intended both systems are very close. In Japanese to English TranslateGemma shows regressions caused mainly by named business errors, or other categories of errors improve.
Multimodal translation and developer interface
TranslateGemma inherits the image recognition stack of Gemma 3. The research team tests image translation on the Vistra benchmark. They selected 264 images each containing one text example. The model only receives the image and the command you ask it to translate the text in the image. There is no separate bounding box input and no clear OCR step.
In this setting, TranslateGemma 27B improves MetricX from 2.03 to 1.58 and Comet22 from 76.1 to 77.7. The 4B variant shows small but positive gains. Model 12B improves on MetricX but has slightly lower Comet22 results than the original. Overall, the research team concluded that TranslateGemma maintains the multimodal capability of Gemma 3 and that improvements in text translation generally extend to image translation.
Key Takeaways
- TranslateGemma is a special version of Gemma 3 for translation: TranslateGemma is an open translation model scheme based on Gemma 3, with parameter sizes of 4B, 12B and 27B, optimized for 55 languages using a two-stage pipeline, supervised fine-tuning and reinforcement learning with translation-oriented rewards.
- Training combines Gemini synthetic data with corresponding human corpora: Models are fine-tuned on a combination of high-quality synthetic data generated by Gemini and interpreted human data, improving the availability of both high-resource and low-resource languages while preserving the traditional LLM capabilities in Gemma 3.
- Reinforcement learning uses qualitative measurement rewards: After good supervised configuration, TranslateGemma uses reinforcement learning driven by a combination of reward models, including MetricX QE and AutoMQM, which clearly targets translation quality and fluency rather than normal conversational behavior.
- The smaller models match or beat the larger Gemma 3 bases in WMT24++: On WMT24++ across 55 languages, all sizes of TranslateGemma show a consistent improvement over Gemma 3, the 12B model surpasses the base 27B Gemma 3 and the 4B model achieves a quality comparable to the base 12B, which reduces the computational requirements of the translation quality level.
- Models retain multimodal capabilities and are released as open weights: TranslateGemma retains the image text translation capabilities of Gemma 3 and improves performance in the Vistra image translation benchmark, and weights are extracted as open models in Hugging Face and Vertex AI, allowing local and cloud applications.
Check out Paper, Model weights again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the power of Artificial Intelligence for the benefit of society. His latest endeavor is the launch of Artificial Intelligence Media Platform, Marktechpost, which stands out for its extensive coverage of machine learning and deep learning stories that sound technically sound and easily understood by a wide audience. The platform boasts of more than 2 million monthly views, which shows its popularity among viewers.



