NVIDIA AI Open-Sourced KVzap: SOTA KV Cache Pruning Method Delivers Near Lossless 2x-4x Compression

As the context length moves to tens and hundreds of thousands of tokens, the key-value cache in transformer decoders becomes the first supply bottleneck. The cache stores the keys and values of all the layers and the shape head (2, L, H, T, D). For a vanilla converter like Llama1-65B, the cache is up to about 335 GB for 128k tokens in bfloat16, which directly limits the batch size and increases the time to the first token.
Structural compression leaves the sequence axis unaffected
Production models are already pushing the cache on several axes. Combined Query Analysis shares keys and values across multiple queries and displays 4 compression factors for Llama3, 12 for GLM 4.5 and up to 16 for Qwen3-235B-A22B, across the head axis. DeepSeek V2 compresses the key and size of the value with Multi head Latent Attention. Hybrid models combine attention with sliding window attention or space layers to reduce the number of layers that store a full cache.
These changes do not compress the sequence axis. Minimal style attention and retrieval only retrieves a subset of the cache at each encoding step, but all tokens still take up memory. Therefore efficient long context usage requires strategies that remove cache entries that will negatively impact future tokens.
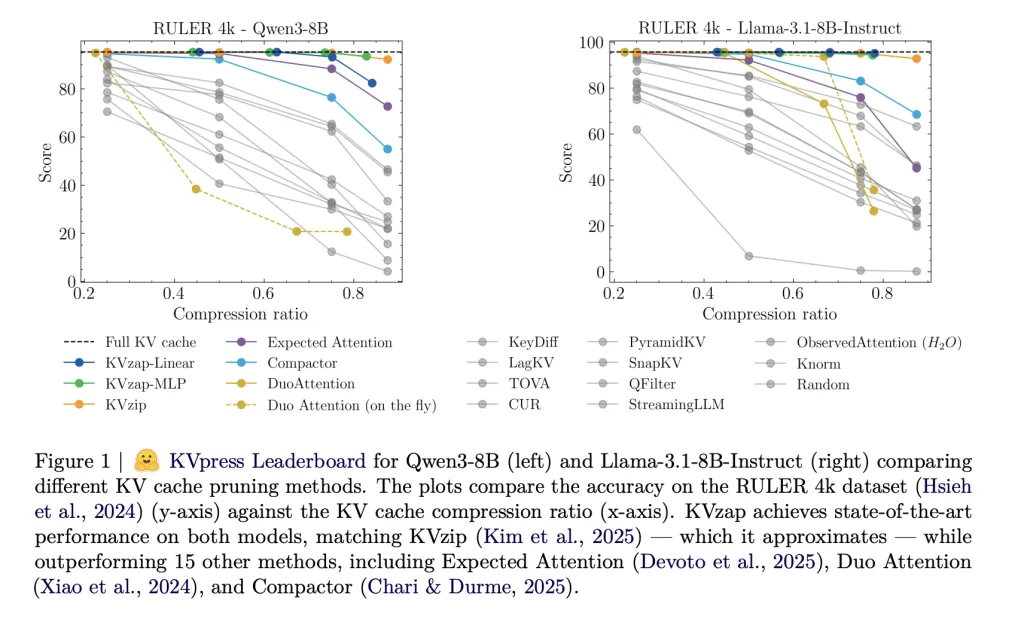
The KVpress project from NVIDIA collects more than twenty such pruning methods in a single codebase and presents them through a public leaderboard on Hugging Face. Methods like H2O, Anticipatory Attention, DuoAttention, Compactor and KVzip are all tested consistently.
KVzip and KVzip plus as a scoring oracle
KVzip is currently the strongest archive pruning site on the KVpress leaderboard. It describes the key points of each cache installation using the copy and paste function. The model works with extended information when asked to reproduce the original context exactly. For each token position in the first command, the score is the maximum attention weight given to any position in the sequence that is repeated in that token, across all heads in the same group when using the clustered query attention. Entries with low results are removed until the global budget is met.
KVzip+ improves this score. It multiplies the attention weight by the norm of the value of the contribution to the residual stream and adapts the norm to accept the hidden state. This better matches the actual change the token brings to the residual stream and improves the correlation and accuracy of the stream compared to the original result.
These oracle points are effective but expensive. KVzip requires pre-filling in extended information, which doubles the length of the content and makes it more accurate in production. And it can’t work at runtime because the scoring process takes a lot of input.
KVzap, a surrogate model in hidden regions
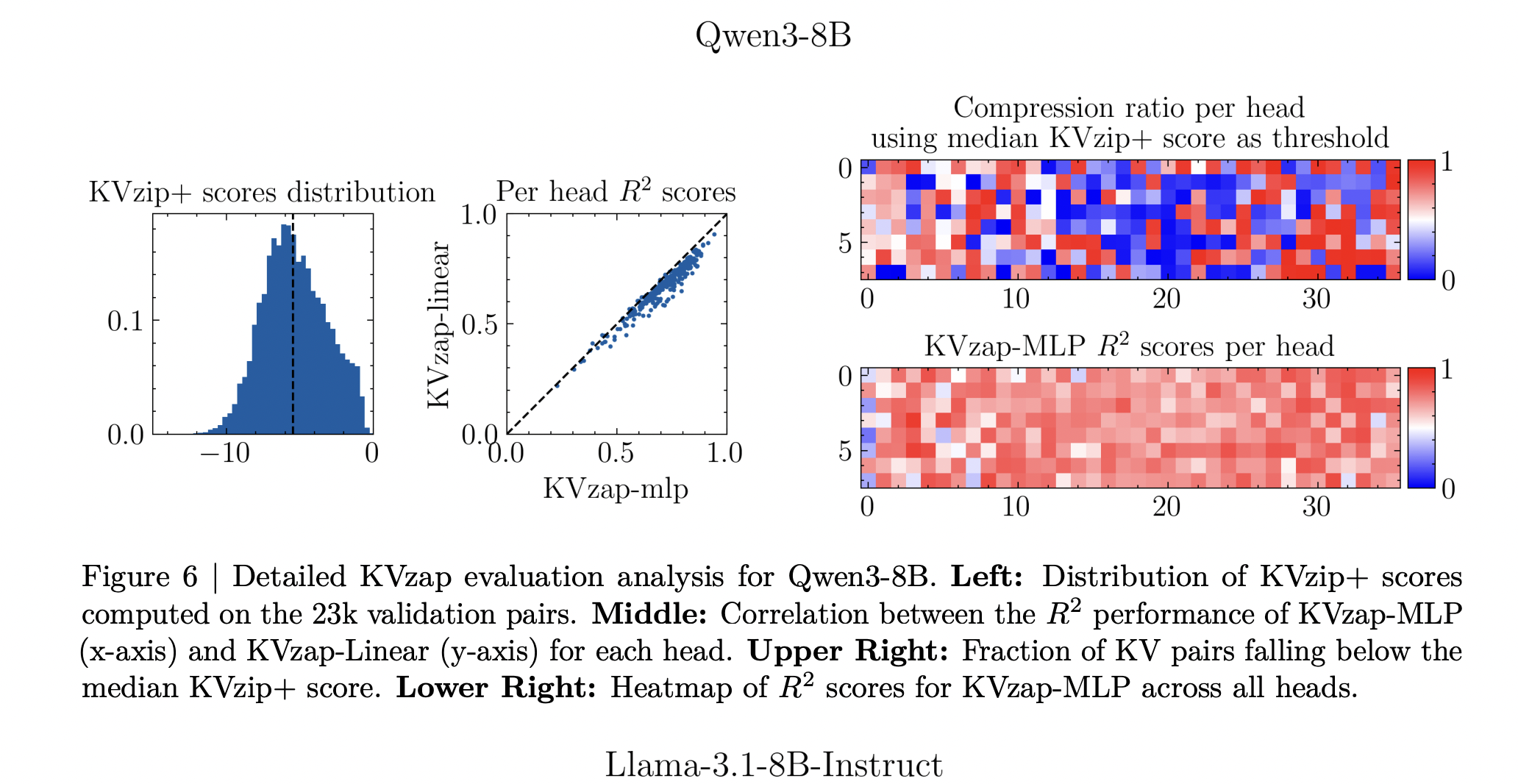
KVzap replaces the oracle with a small replacement model that works directly on hidden regions. For each layer of the transformer and for each state of the t sequence, the module finds the hidden vector hₜ and the predicted results of the log scores of every key of the head value. Two architectures are considered, one linear layer (KVzap Linear) and two layer MLP with GELU and hidden width equal to one eighth of the hidden size of the model (KVzap MLP).
Training uses information from the Nemotron Pretraining sample dataset. The research team’s 27k filter goes to a length between 750 and 1,250 tokens, samples up to 500 pieces of information per set, and then samples 500 token locations quickly. For each key-value head they get about 1.2 million training pairs and a validation set of 23k pairs. The proxy learns to reverse from the hidden state to the KVzip+ log output. For all models, the Pearson’s squared correlation between prediction and oracle scores reaches between 0.63 and 0.77, the MLP variant performing better than the linear variant.
Thresholding, sliding windowing and negligible overhead
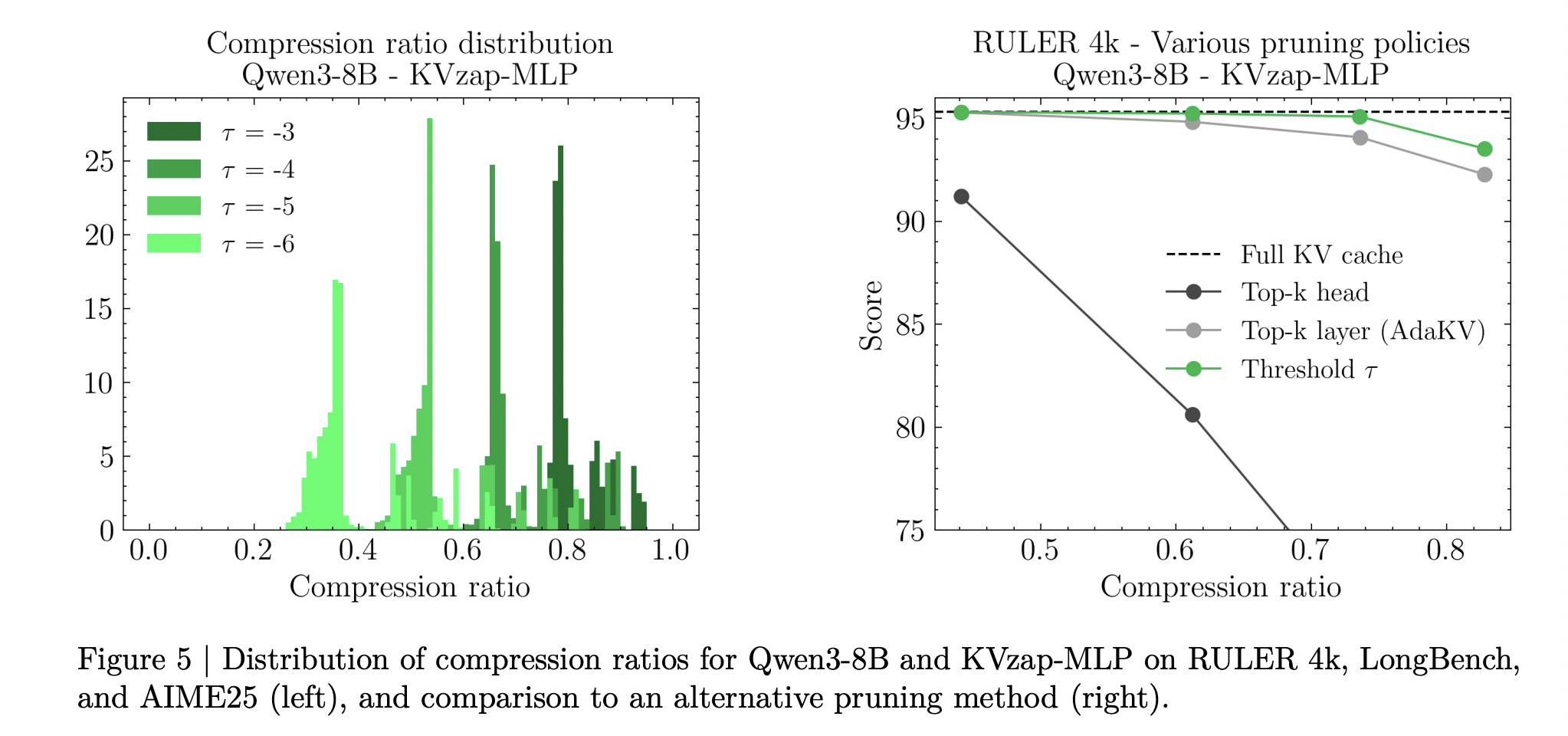
During inference, the KVzap model processes hidden instances and generates a score for each cache entry. Entries with scores below a fixed threshold are pruned, while a sliding window of the latest 128 tokens is always maintained. The research team provides a short PyTorch-style function that executes the model, sets the local window points to infinity and returns the pressed key and value parameters. In all experiments, castration is applied after attentional activation.
KVzap uses point thresholding instead of choosing a fixed upper limit. A single threshold produces different compression ratios that apply to different benchmarks and even to all commands within the same benchmark. The research team reports a 20 percent variation in the compression ratio across commands at the fixed limit, reflecting differences in information density.
Counting up is small. A layer-level analysis shows that the additional cost of KVzap MLP is about 1.1 percent of the FLOPs of the linear projection, while the linear variant adds about 0.02 percent. The relative memory head follows the same values. In long-context settings, quadratic attention costs dominate and therefore additional FLOPs are ignored.
Results in RULER, LongBench and AIME25
KVzap is tested with long context and logic benchmarks using Qwen3-8B, Llama-3.1-8B Instruct and Qwen3-32B. Long context behavior is measured in RULER and LongBench. RULER runs synthetic jobs with sequence lengths from 4k to 128k tokens, while LongBench uses real-world scripts from many classes of jobs. AIME25 provides a mathematical reasoning workload with 30 Olympiad-level problems assessed under 1 pass and 4 passes.
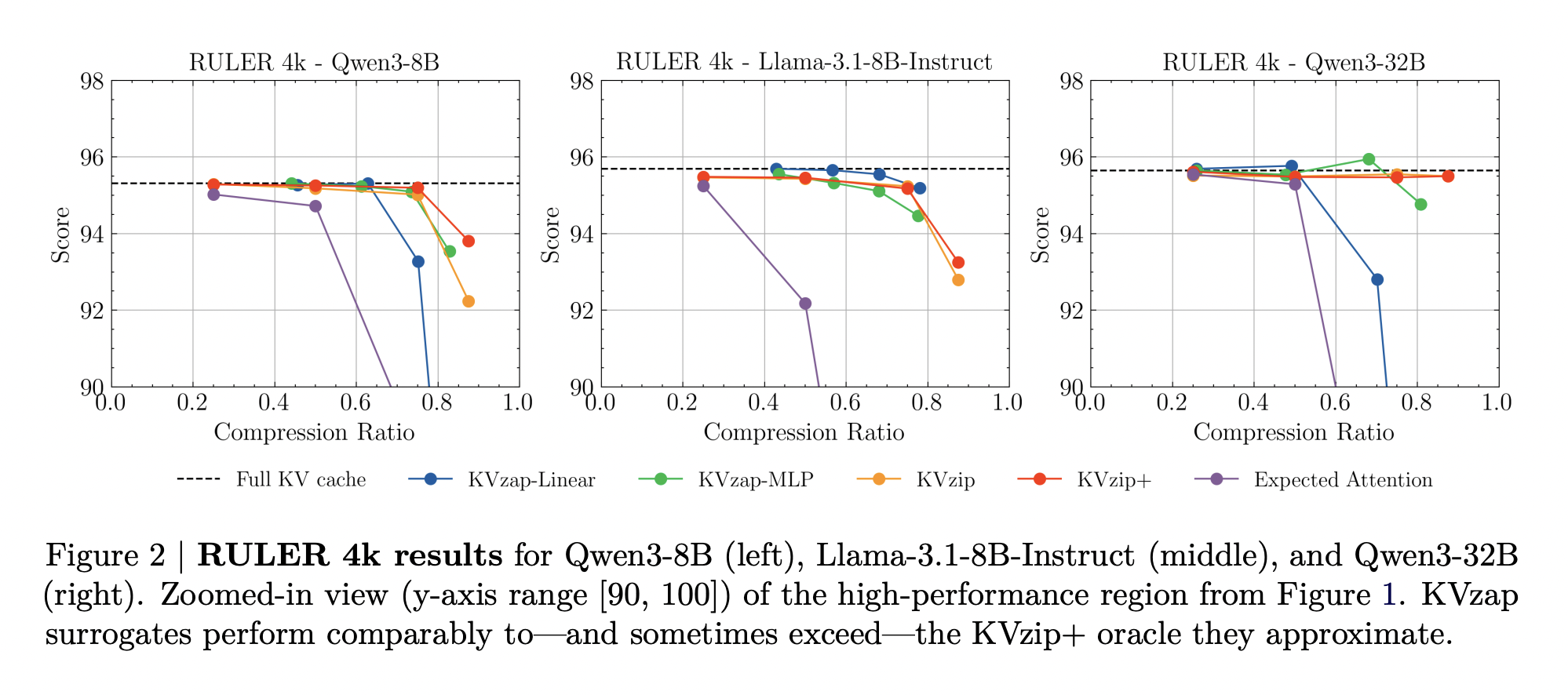
In RULER, KVzap matches the full base cache within a small accuracy margin while extracting most of the cache. For Qwen3-8B, the best KVzap configuration achieves an extracted fraction above 0.7 for RULER 4k and 16k while keeping the average score within a few tenths of the full cache score. Similar behavior holds for Llama-3.1-8B Instruct and Qwen3-32B.
In LongBench, the same thresholds lead to lower compression rates because the scripts are less repetitive. KVzap stays close to the absolute base of the cache up to about 2 to 3 times the compression, while fixed budget methods like Expected Attention degrade significantly in several subsets when the compression is increased.
In AIME25, KVzap MLP maintains or slightly improves the pass with 4 accuracy in compression close to 2 times and remains usable even when discarding more than half of the cache. Extremely aggressive settings, for example linear variants at high limits that remove more than 90 percent of entries, degrade performance as expected.
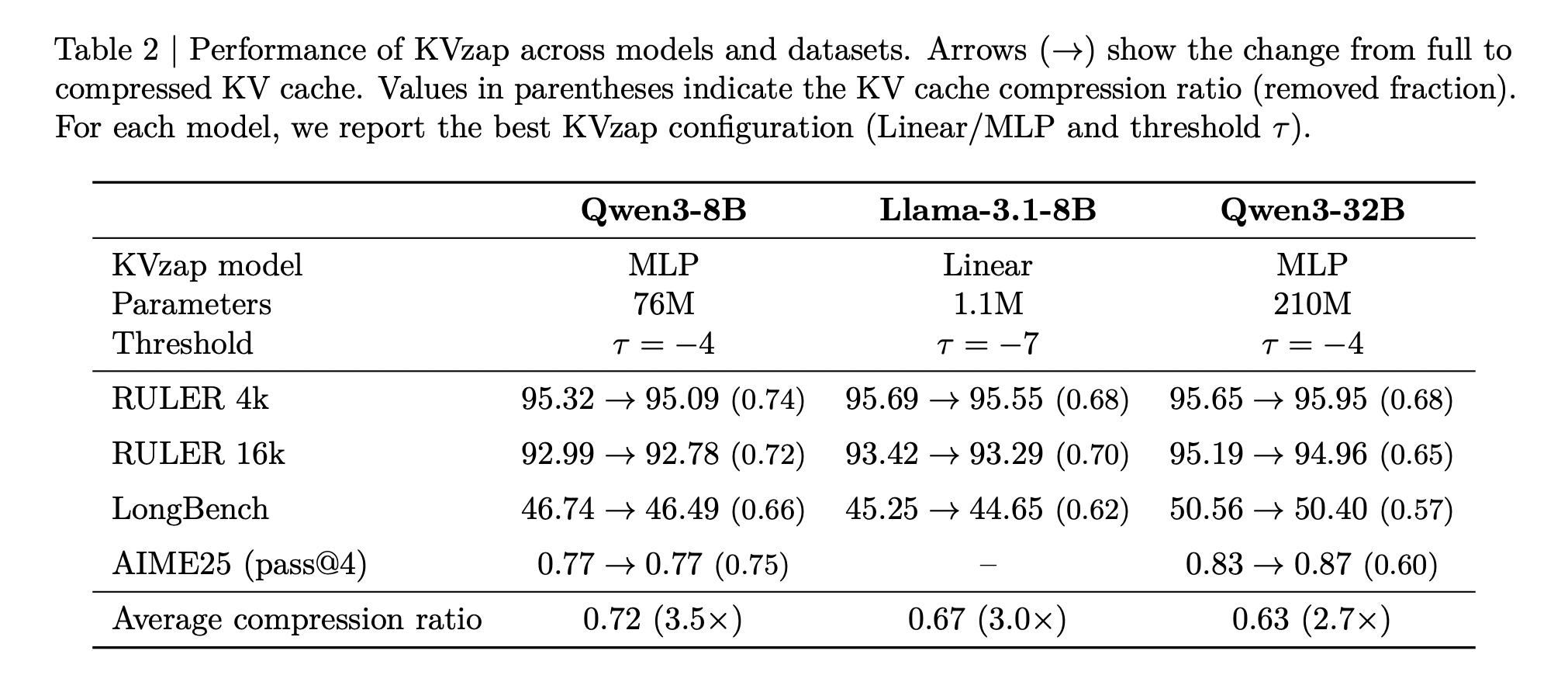
Overall, the Table above shows that the best KVzap configuration for each model delivers an average cache compression between about 2.7 and 3.5 while maintaining performance scores very close to the full cache baseline across RULER, LongBench and AIME25.
Key Takeaways
- KVzap is an adaptive input approximation of KVzip+ that learns to predict the oracle KV value points in hidden regions using layer-by-layer resistance models, linear layer or shallow MLP, and then prunes the low-score KV pairs.
- Training uses Nemotron pretraining information where KVzip+ provides supervision, generating approximately 1.2 million examples per head and achieving a squared correlation in the range of 0.6 to 0.8 between the predicted score and the oracle, which is sufficient to measure the importance of a reliable cache.
- KVzap uses a global score threshold with a fixed sliding window of recent tokens, so compression automatically adapts to reduce information, and the research team reports a 20 percent variation in compression achieved across instructions at the same threshold.
- On Qwen3-8B across, Llama-3.1-8B Instruct and Qwen3-32B on RULER, LongBench and AIME25, KVzap achieves about 2 to 4 times the compression of KV cache while maintaining accuracy very close to full cache, and achieves high trading on the NVIDIA KVpress Leader board.
- The extra compute is minimal, about 1.1 percent more FLOP than the MLP variant, and KVzap is implemented in the open source kvpress framework that is ready to use checkpoints in Hugging Face, making it useful to integrate existing LLM stacks in use.
Check out Paper again GitHub Repo. Also, feel free to follow us Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the power of Artificial Intelligence for the benefit of society. His latest endeavor is the launch of Artificial Intelligence Media Platform, Marktechpost, which stands out for its extensive coverage of machine learning and deep learning stories that sound technically sound and easily understood by a wide audience. The platform boasts of more than 2 million monthly views, which shows its popularity among viewers.



