Alibaba Introduces Qwen3-Max-Thinking, a Scaled Test-Time Model for Consulting a Native Tool Using Agentic Workloads

Qwen3-Max-Thinking is Alibaba’s new dominant thinking model. It not only measures parameters, it also changes the way it is thought, with clear control over the depth of thought and built in search, memory, and coding tools.
Model scale, data, and implementation
Qwen3-Max-Thinking is a trillion-parameter MoE LLM pretrained on 36T tokens and built on the Qwen3 family as a high-level thinking model. The model guides long-horizon thinking and coding, not just casual conversation. It works with a context window of 260k tokens, supporting cache-scale code, long technical reports, and multi-document analysis within a single database.
Qwen3-Max-Thinking is a closed model provided by Qwen-Chat and Alibaba Cloud Model Studio with an OpenAI compatible HTTP API. The same conclusion can be called for a Claude-style tool schema, so that existing Anthropic or Claude Code flows can be exchanged for Qwen3-Max-Thinking with minor changes. There are no public weights, so the implementation is based on the API, which is similar to its positionin
Smart Test Time Scaling and incremental thinking experience
Many large language models improve reasoning by scaling simple test times, for example best of N sampling with several parallel chains of reasoning. That method increases the quality but the cost increases almost in proportion to the number of samples. Qwen3-Max-Thinking presents a multi-round test time scaling strategy.
Instead of taking multiple samples only in parallel, the model iterates over the course of a single conversation, reusing central thought traces as structured experiences. After each round, it draws partial useful conclusions, and then focuses the next calculation on the unsolved parts of the question. This process is controlled by a transparent thinking budget that developers can adjust using API parameters such as enable_thinking and additional adjustment fields.
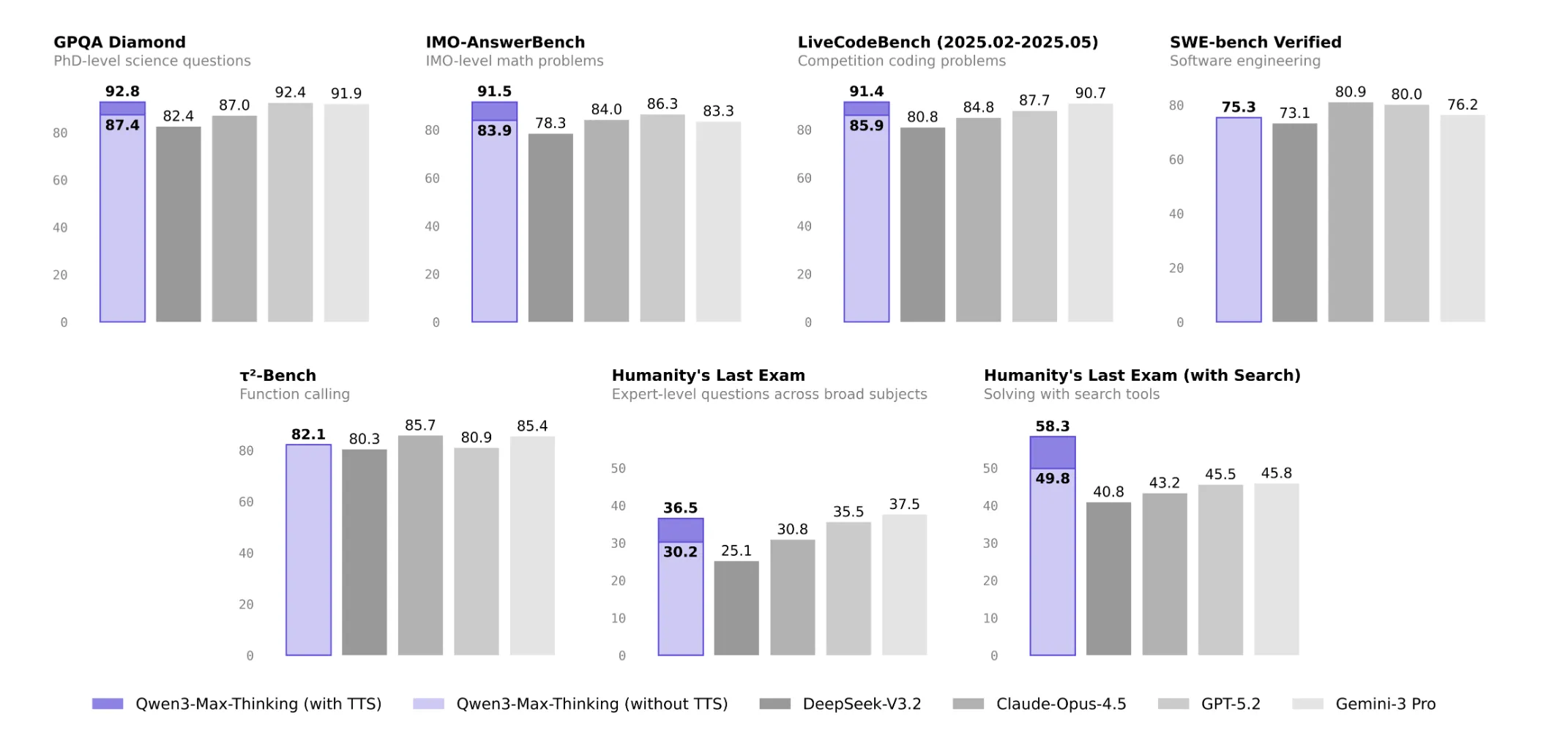
The reported effect is that accuracy increases without a commensurate increase in the number of tokens. For example, Qwen’s own release shows GPQA Diamond increasing from an accuracy level of 90 to about 92.8, and LiveCodeBench v6 increasing from about 88.0 to 91.4 under the strategy of gathering information on the same token budgets. This is important because it means that higher imaging quality can be driven by more efficient computer scheduling, not just more samples.
A native agent stack Using the Dynamic Tool
Qwen3-Max-Thinking includes three tools as first-class skills: Search, Memory, and Code Interpreter. Search connects to web retrieval so the model can fetch new pages, extract content, and focus its responses. Memory stores the state of a user or a specific session, supporting personalization for long-term workflows. The Code Interpreter uses Python, which allows code verification, data transformation, and program integration with runtime testing.
The model uses Adaptive Tool Use to determine when to call these tools during a conversation. Tool calls interact with internal logic components, rather than being programmed by an external agent. This design reduces the need for separate routers or programmers and tends to reduce false positives, because the model can clearly retrieve missing information or verify statistics instead of guesswork.
The ability of the tool is also measured. In the Tau² benchmark, which measures the workload and orchestration of tools, the Qwen3-Max-Thinking reports a score of 82.1, compared to other benchmark models in this category.
Benchmark profile for all information, reasoning, and search
In 19 public benchmarks, Qwen3-Max-Thinking ranked at or near the same level as GPT 5.2 Thinking, Claude Opus 4.5, and Gemini 3 Pro. On informational tasks, reported scores included 85.7 on MMLU-Pro, 92.8 on MMLU-Redux, and 93.7 on C-Eval, with Qwen leading the pack on the Chinese language test.
With strong reasoning, it scores 87.4 on GPQA, 98.0 on HMMT Feb 25, 94.7 on HMMT Nov 25, and 83.9 on IMOAnswerBench, placing it in the top tier of current math and science models. In coding and software engineering it scores 85.9 on LiveCodeBench v6 and 75.3 on SWE Verified.
Based on the HLE configuration the Qwen3-Max-Thinking scores 30.2, below the Gemini 3 Pro at 37.5 and the GPT 5.2 Thinking at 35.5. On a device with the HLE setup enabled, the official comparison table that includes web search integration shows Qwen3-Max-Thinking at 49.8, ahead of GPT 5.2 Thinking at 45.5 and Gemini 3 Pro at 45.8. In its most powerful cumulative experience of the test time configuration in HLE with tools, Qwen3-Max-Thinking reaches 58.3 while GPT 5.2 Thinking remains at 45.5, although that higher number is for heavy inference mode rather than a standard comparison table.
Key Takeaways
- Qwen3-Max-Thinking is a closed, API-only thinking model from Alibaba, built on a multi-parameter backbone trained on about 36 trillion tokens with a total token window of 262144.
- The model introduces cumulative test time scaling, where it reuses average logic across multiple rounds, outperforming benchmarks such as GPQA Diamond and LiveCodeBench v6 for similar token budgets.
- Qwen3-Max-Thinking includes Search, Memory, and Code Interpreter as native tools and uses Adaptive Tool Use so that the model itself can decide when to browse, remember state, or sign Python during a conversation.
- In public benchmarks it reports scores that rival GPT 5.2 Thinking, Claude Opus 4.5, and Gemini 3 Pro, including strong results in MMLU Pro, GPQA, HMMT, IMOAnswerBench, LiveCodeBench v6, SWE Bench Verified, and Tau² Bench.
Check it out API and technical details. Also, feel free to follow us Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.

Michal Sutter is a data science expert with a Master of Science in Data Science from the University of Padova. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at turning complex data sets into actionable insights.



