Liquid AI Releases LFM2.5: A Unified Family Model for Real AI on Device Agents

Liquid AI has introduced the LFM2.5, a new generation of basic micromodels built on the LFM2 architecture and focused on device and edge applications. The model family includes the LFM2.5-1.2B-Base and LFM2.5-1.2B-Yala and expands to Japanese, visual language, and audio language variations. It is released as open weights on Hugging Face and presented on the LEAP platform.
Recipe for construction and training
LFM2.5 maintains the architecture of the hybrid LFM2 that was designed to be defined in a fast and memory-efficient manner on CPUs and NPUs and scale data and a post-training pipeline. The pre-training of the 1.2 billion parameter backbone is expanded from 10T to 28T tokens. Teaching alternatives then receive supervised fine-tuning, preferred alignment, and reinforced multi-level learning that focuses on subsequent learning, tool use, math, and reasoning skills.
Text model performance at the scale of one billion
LFM2.5-1.2B-Yala is a general purpose text model. The Liquid AI team reports benchmark results in GPQA, MMLU Pro, IFEval, IFBench, and several calling and coding suites. The model scores 38.89 in GPQA and 44.35 in MMLU Pro. Competitive 1B class open models such as Llama-3.2-1B Instruct and Gemma-3-1B IT score the lowest in these metrics.
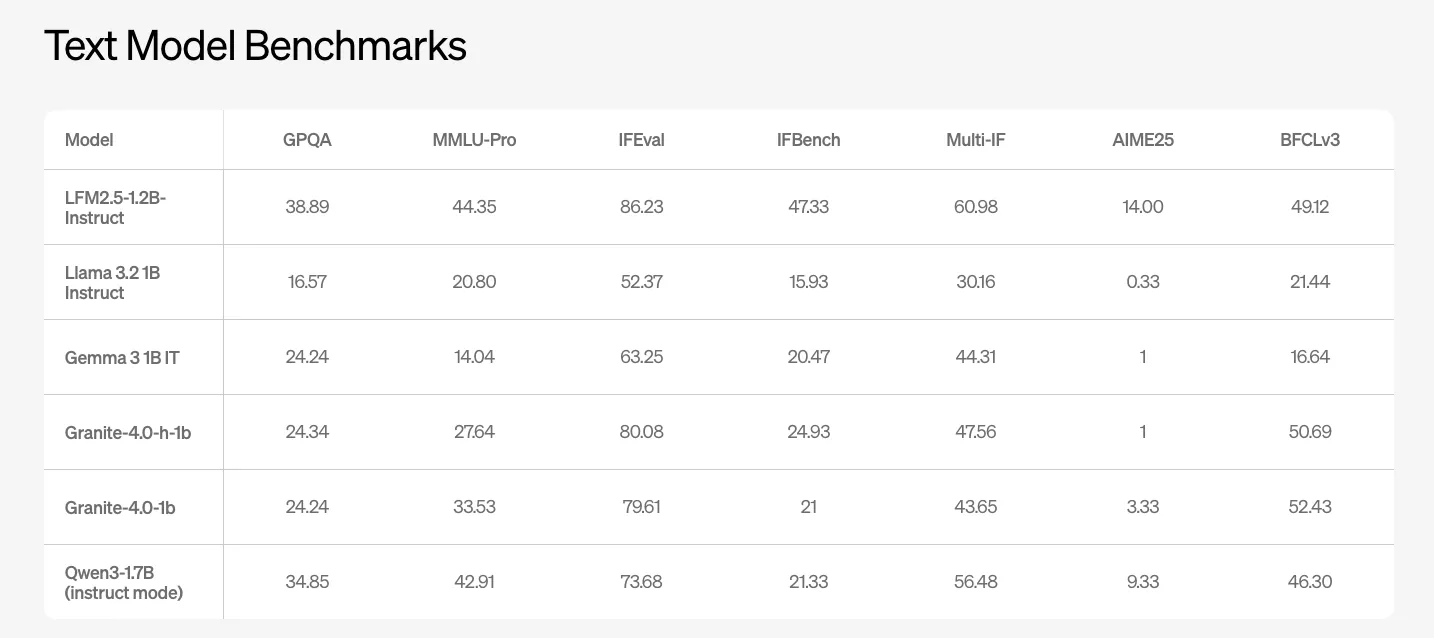
In IFEval and IFBench, which target multi-step instructions and call quality, the LFM2.5-1.2B-Instruct reports 86.23 and 47.33. These values are ahead of the other 1B class bases in the Liquid AI table above.
A variant prepared for Japanese
LFM2.5-1.2B-JP is a Japanese optimized text model available on the same core. It targets functions such as JMMLU, M-IFEval in Japanese, and GSM8K in Japanese. This benchmark improves upon the standard instructional model for Japanese tasks and competes with or surpasses other small multilingual models such as Qwen3-1.7B, Llama 3.2-1B Instruct, and Gemma 3-1B IT in these localized benchmarks.
A conceptual linguistic model of multimodal edge workloads
LFM2.5-VL-1.6B is the new vision language model in the series. It uses LFM2.5-1.2B-Base as the core of the language and adds a vision tower for image recognition. The model is tuned to a wide range of visual imaging and OCR benchmarks, including MMStar, MM IFEval, BLINK, InfoVQA, OCRBench v2, RealWorldQA, MMMU, and multilingual MMBench. The LFM2.5-VL-1.6B improves on the previous LFM2-VL-1.6B in many metrics and is intended for real-world tasks such as document understanding, user interface reading, and multi-image imaging under edge constraints.
An audio language model with native speech
LFM2.5-Audio-1.5B is a native audio language model that supports both text and audio input and output. It is presented as an Audio-to-Audio model and uses a de-tokenizer that is eight times faster than the previous Mimi-based detokenizer with the same hardware-encoded accuracy.
The model supports two main production methods. Intermittent generation is designed for real-time speech to conversational agents where latency dominates. Sequential generation is intended for tasks such as automatic speech recognition and text-to-speech and allows changing the generated method without updating the model. The noise stack is trained by low-accuracy low-accuracy calibration, which keeps metrics like STOI and UTMOS close to a full-accuracy baseline while allowing for use on devices with limited computing power.
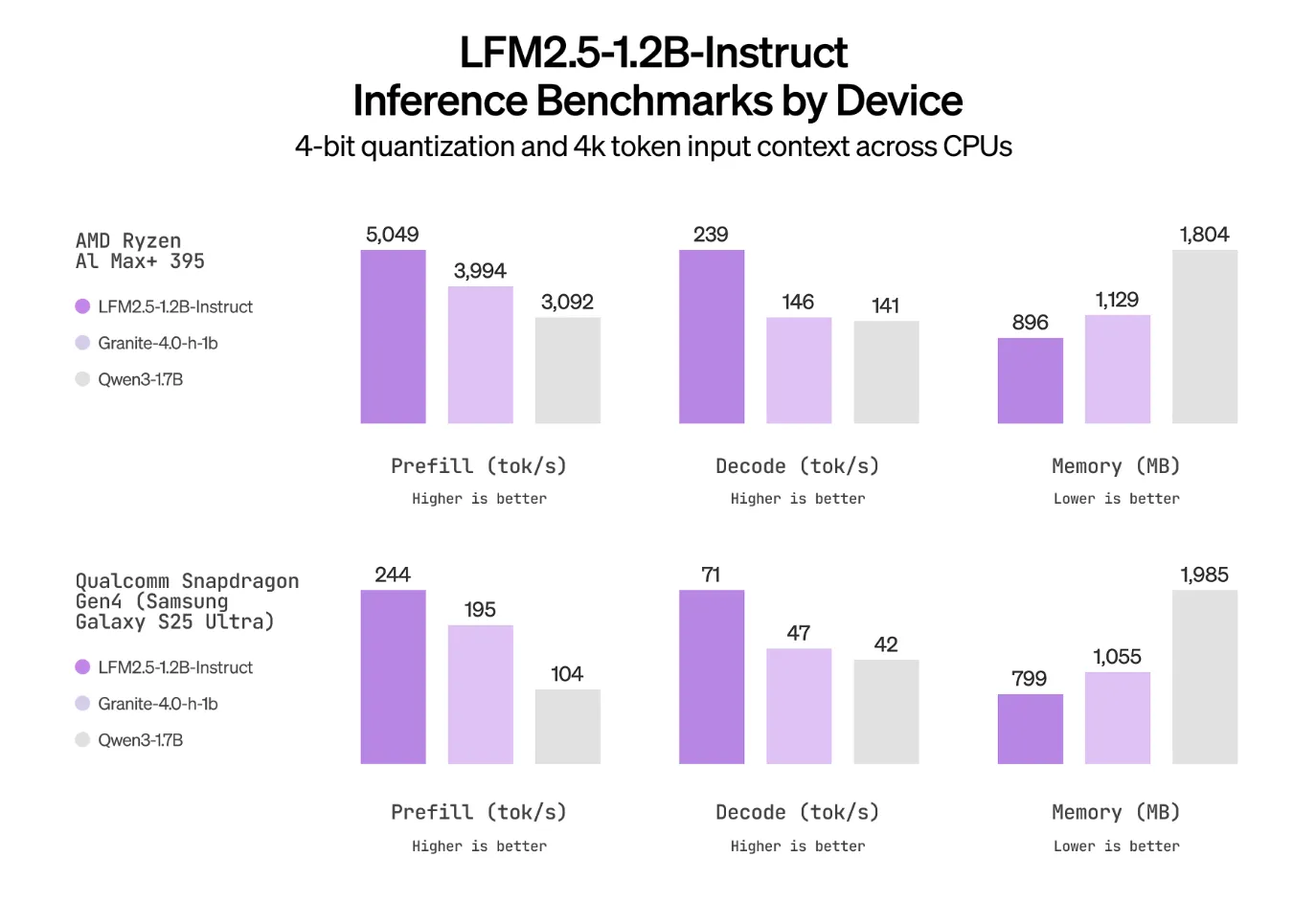
Key Takeaways
- LFM2.5 is a 1.2B scale hybrid model family built on the LFM2 device with advanced features, with variations of Base, Instruct, Japanese, Vision Language, and Audio Language, all released as open weights on Hugging Face and LEAP.
- LFM2.5 pre-training from 10T to 28T tokens and the Instruction model adds supervised fine-tuning, preference alignment, and massive multi-stage reinforcement learning, pushing instruction tracking and tooling quality beyond other class 1B bases.
- LFM2.5-1.2B-Instruct delivers solid text benchmark performance at 1B scale, reaching 38.89 in GPQA and 44.35 in MMLU Pro with leading peer models such as Llama 3.2 1B Instruct, Gemma 3 1B IT, and Granite 4.0 1B in IFEBench.
- The family includes unique multimodal and regional variants, with the LFM2.5-1.2B-JP achieving state-of-the-art Japanese benchmarks in its scale and the LFM2.5-VL-1.6B and LFM2.5-Audio-1.5B covering visual language and native audio edge workloads.
Check it out Technical details again Model weights. Also, feel free to follow us Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Check out our latest issue of ai2025.deva 2025-focused analytics platform that transforms model implementations, benchmarks, and ecosystem activity into structured datasets that you can sort, compare, and export
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the power of Artificial Intelligence for the benefit of society. His latest endeavor is the launch of Artificial Intelligence Media Platform, Marktechpost, which stands out for its extensive coverage of machine learning and deep learning stories that sound technically sound and easily understood by a wide audience. The platform boasts of more than 2 million monthly views, which shows its popularity among viewers.



