MBZUAI Releases K2 Think V2: The 70B Fully-Dominated Thinking Model for Math, Coding, and Science

Does the fully open thinking model fit the state of the art programs where all parts of its training pipeline are transparent. Researchers from Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) release K2 Think V2, a fully autonomous thinking model designed to test how open and fully documented pipelines can push long-horizon thinking in mathematics, code, and science when the entire stack is open and iterative. K2 Think V2 takes the 70 billion parameter K2 V2 Instruction base model and uses a rigorous reinforcement learning method to transform it into an accurate thinking model that is always fully open to both weights and data.

From the basic K2 V2 model to the professional thinker
K2 V2 is a transformer-only decoder with 80 layers, hidden size 8192, and 64 heads with clustered query attention and embedded rotary fields. It is trained on nearly 12 billion tokens taken from TxT360 and selected related datasets including web text, statistics, code, multilingual data, and scientific documents.
The training proceeds in three phases. Pre-training works with a context length of 8192 tokens on natural data to obtain robust general information. Intermediate training then expands the context up to 512k tokens using TxT360 Midas, which mixes long documents, integrated thought traces, and various thought behaviors while carefully preserving at least 30 percent short context data for every section. Finally, the supervised fine tuning, called TxT360 3efforts, includes step-by-step instructions and systematic thinking signals.
The important point is that the K2 V2 is not a standard base model. It is clearly prepared for long-term contextual consistency and exposure to reflective behavior during intermediate training. That makes it a natural basis for a post training class that focuses solely on the quality of thinking, which is exactly what the K2 Think V2 does.
The fully dominant RLVR in the GURU dataset
The K2 Think V2 is trained with a GRPO RLVR style recipe in addition to the K2 V2 Instruct. The team uses the Guru dataset, version 1.5, which focuses on math, coding, and STEM questions. Guru is derived from licensed sources, expanded to include STEM, and benchmarked against key testing benchmarks before use. This is important for an independent claim, because both the basic model data and the RL data are selected and documented by the same institution.
The GRPO setup removes the common KL loss and the auxiliary entropy and uses a proportional policy rate cut with an upper cut set to 0.28. The training runs fully on the policy with a temperature of 1.2 to maximize output diversity, a global cluster size of 256, and no small overlap. This avoids policy adjustments which are known to introduce instability into GRPO such as training.
The RLVR itself works in two stages. In the first stage, the response length is set to 32k tokens and the model is trained for about 200 steps. In the second phase, the length of the large response increases to 64k tokens and the training continues for about 50 steps with the same hyperparameter. This program directly uses the long context capability inherited from K2 V2 so that the model can practice the full range of thought processes rather than short solutions.
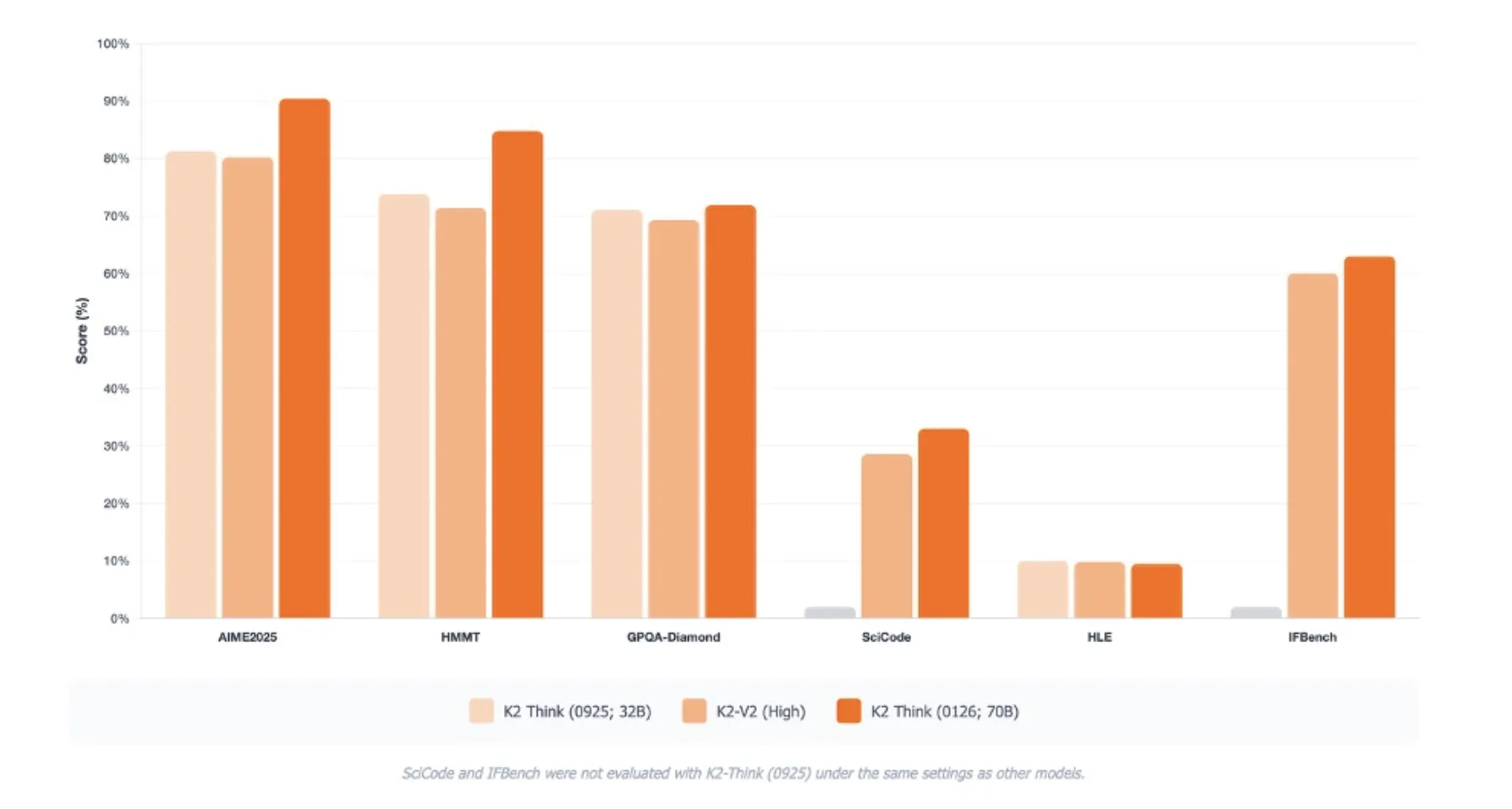
Benchmark profile
K2 Think V2 targets thinking benchmarks rather than just information measurements. In AIME 2025 it achieves 1st pass out of 90.42. In HMMT 2025 he scored 84.79. In GPQA Diamond, the scientific benchmark for the hardest level, it reaches 72.98. In SciCode it scores 33.00, and in Humanity’s Last Exam it reaches 9.5 under default settings.
These scores are reported as averages over 16 runs and are directly comparable only within the same experimental protocol. The MBZUAI team also highlights the improvement of IFBench and the Artificial Intelligence test system, as well as some advantages of optical visualization and long-term contextual thinking compared to the previous K2 Think release.
Safety and openness
The research team reports an analysis of the Safety 4 style that includes four areas of safety. Content and social security, truth and honesty, and social alignment all reach high average risk levels in the low range. Data and infrastructure risks remain high and are marked as critical, reflecting concerns about the management of sensitive personal information rather than a behavioral model alone. The team says that the K2 Think V2 still shares the usual limitations of the main language models despite this reduction. In Artificial Analysis’s Openness Index, K2 Think V2 sits on the border with K2 V2 and Olmo-3.
Key Takeaways
- The K2 Think V2 is a fully self-contained 70B model: Built on K2 V2 Instruction, with open weights, open data recipes, detailed training logs, and a full RL pipeline released with Reasoning360.
- The basic model was developed for long context and thinking before RL: K2 V2 is a dense decoder converter trained on approximately 12T tokens, with intermediate training extending the context length to 512K tokens and supervised ‘3-attempts’ SFT targeting systematic reasoning.
- Constraints were aligned using GRPO based on RLVR on the Guru dataset: Training uses stage 2 in GRPO policy setting in Guru v1.5, with asymmetric cut, temperature 1.2, and response caps at 32K and then 64K tokens to learn a long series of thought solutions.
- Competitive effects on cognitive benchmarks: K2 Think V2 reports strong passing 1 scores such as 90.42 in AIME 2025, 84.79 in HMMT 2025, and 72.98 in GPQA Diamond, positioning it as a high precision clear thinking model for math, coding, and science.
Check it out Paper, Model Weight, Repo and Technical Details. Also, feel free to follow us Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Max is an AI analyst at MarkTechPost, based in Silicon Valley, who is actively shaping the future of technology. He teaches robots at Brainvyne, fights spam with ComplyEmail, and uses AI every day to translate complex technological advances into clear, understandable information.



