Tavus Introduces Phoenix-4: Gaussian-Diffusion Model Brings Real-Time Emotional Intelligence and Sub-600ms Latency to Generative Video AI

The ‘mysterious valley’ is the final frontier of video production. We’ve seen AI avatars that can talk, but they often lack the soul of human interaction. They suffer from rigid movements and lack of emotional context. Tavus aims to remedy this with the introduction of Phoenix-4A new productive AI model designed for Conversational Video Interface (CVI).
Phoenix-4 represents a transition from static video generation to dynamic, real-time human rendering. It’s not just about moving the lips; it’s about creating a digital persona that sees, moments, and reacts with emotional intelligence.
Three Powers: Raven, Sparrow, and Phoenix
To achieve true realism, Tavus uses a 3-part model structure. Understanding how these models interact is important for developers who want to build interactive agents.
- Raven-1 (Sighting): This model acts as ‘eyes and ears.’ It analyzes the user’s facial expressions and tone of voice to understand the emotional context of the conversation.
- Sparrow-1 (Time): This model controls the flow of the conversation. It decides when the AI should interrupt, pause, or wait for the user to finish, ensuring interactions feel natural.
- Phoenix-4 (Offers): The main production engine. It uses Gaussian distribution to assemble photorealistic video in real time.

Technical Efficiency: Gaussian-Diffusion Supply
Phoenix-4 departs from traditional GAN-based methods. Instead, it uses identity Gaussian-diffusion model. This allows AI to calculate complex facial movements, such as how the stretch of skin affects light or how small expressions appear around the eyes.
This means that the model handles spatial consistency better than previous versions. When the digital person turns his head, the texture and light remain stable. The model produces these very reliable frames at a supporting rate 30 frames per second (fps) stream, which is important in maintaining the illusion of life.
Breaking the Latency Barrier: Sub-600ms
At CVI, speed is everything. If the delay between the user’s speech and the AI’s response is too long, the ‘human’ feeling is lost. Tavus has developed the Phoenix 4 pipeline to achieve end-to-end communication latency of less than 600ms.
This is achieved through a ‘first stream’ design. The model is used WebRTC (Web Real-Time Communication) to stream video data directly to the client’s browser. Rather than generating a full video file and playing it, Phoenix-4 renders and sends video packets incrementally. This ensures that the first frame time is kept to a minimum.
Emotion Regulation System
One of the most powerful features is Emotion Control API. Developers can now clearly describe a person’s emotional state during a conversation.
By passing i emotion parameter in an API request, you can trigger specific behavioral results. The model currently supports key emotional states including:
- Happiness
- Sadness
- Anger
- Surprise
When the emotion is set to happinessThe Phoenix-4 engine adjusts the geometry of the face to create a realistic smile, affecting the cheeks and eyes, not just the mouth. This is the type of conditional video production where the output is influenced by both the text-to-speech phonemes and the emotional vector.
Building with Replicas
Creating a custom ‘Replica’ (digital twin) requires only 2 minutes of training video footage. Once training is complete, Replica can be deployed with the Tavus CVI SDK.
The application is simple:
- Train: Upload it 2 minutes of the person speaking to create something different
replica_id. - Use: use the
POST /conversationsthe end of the first session. - Configure: set the
persona_idas well asconversation_name. - Connect: Link the provided WebRTC URL to your video component at the end.
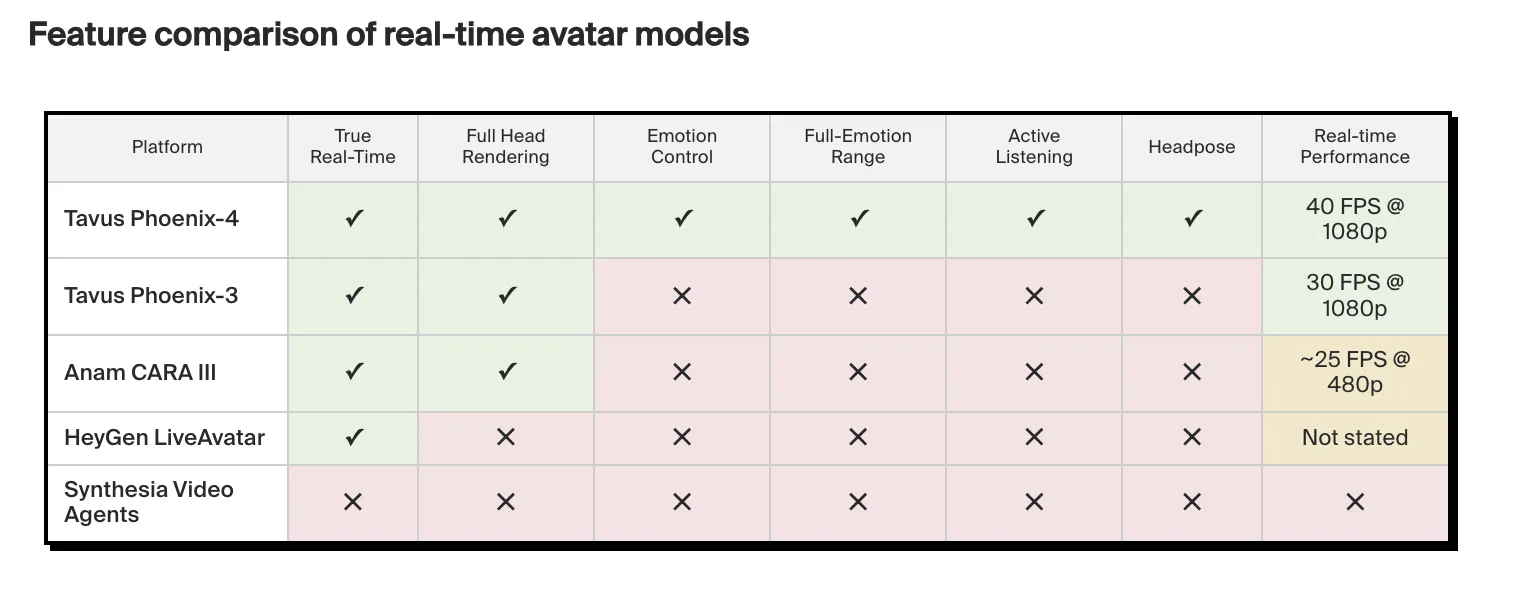
Key Takeaways
- Gaussian-Diffusion Supply: Phoenix-4 goes beyond traditional GANs for implementation Gaussian distributionwhich allows for high-fidelity, realistic facial movement and expressiveness that solves the ‘mysterious valley’ problem.
- AI Trinity (Raven, Sparrow, Phoenix): The architecture is based on three different models: Crow-1 to get a feel for it, Headquarter-1 for chat/turn time, and Phoenix-4 the end of the video.
- Very Low Latency: Optimized for Conversational Video Interface (CVI), the model benefits less than 600ms end-to-end delay, is used WebRTC streaming video packets in real time.
- Mood Management System: You can use the Emotion Control API to specify such states happiness, sadness, anger, or surprisewhich dynamically adjusts the character’s facial geometry and expressions.
- Quick Replica Training: Creating a custom digital twin (‘Replica’) works very well, only requires 2 minutes of video to train different identities for use with the Tavus SDK.
Check it out Technical details, Documentation and Try it here. Also, feel free to follow us Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.




