NVIDIA Releases DreamDojo: An Open World Robot Model Trained on 44,711 Hours of Real-World Human Video Data

Building robot simulators has been a long-standing challenge. Native engines require hand coding of physics and complete 3D models. NVIDIA replaces this with DreamDojoA fully open source, fully customizable robot world model. Instead of using a physics engine, DreamDojo ‘dreams’ the effects of robot actions directly in pixels.

Measuring Robots With 44k+ Hours of Human Experience
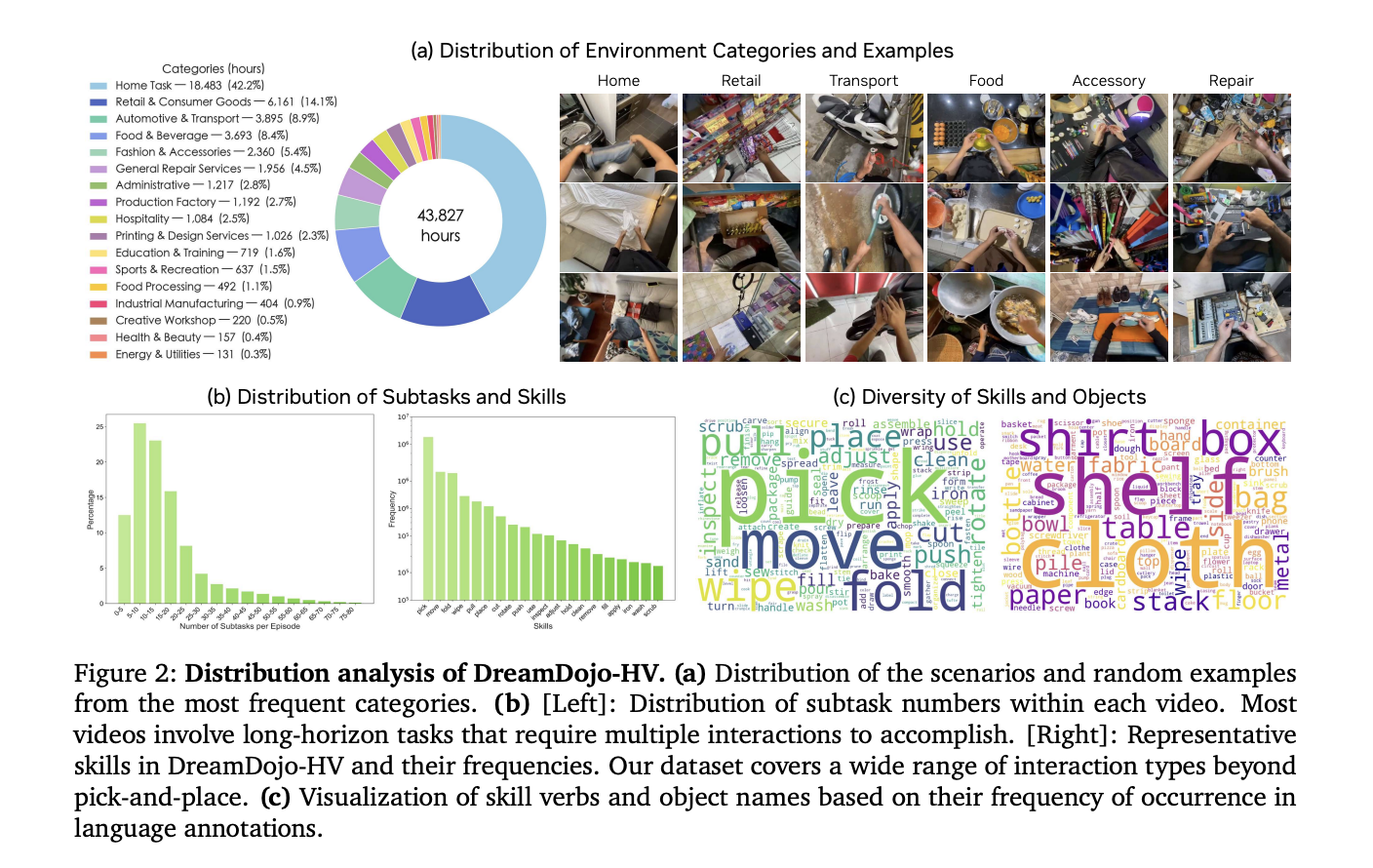
The biggest obstacle for AI in robotics is data. Collecting robot-specific data is expensive and slow. DreamDojo solves this by learning from it 44k+ hours of videos people think about themselves. This dataset, called DreamDojo-HVit is the largest of its kind for global model pre-training.
- It includes 6,015 unique activities across 1M+ trajectories.
- The data includes 9,869 unique scenes and 43,237 unique objects.
- Pretraining used 100,000 NVIDIA H100 GPU hours building variants of the 2B and 14B models.
Humans are already masters of complex physics, such as pouring liquids or folding clothes. DreamDojo uses this human data to give robots a ‘general’ understanding of how the world works.
Bridging the Gap with Subtle Actions
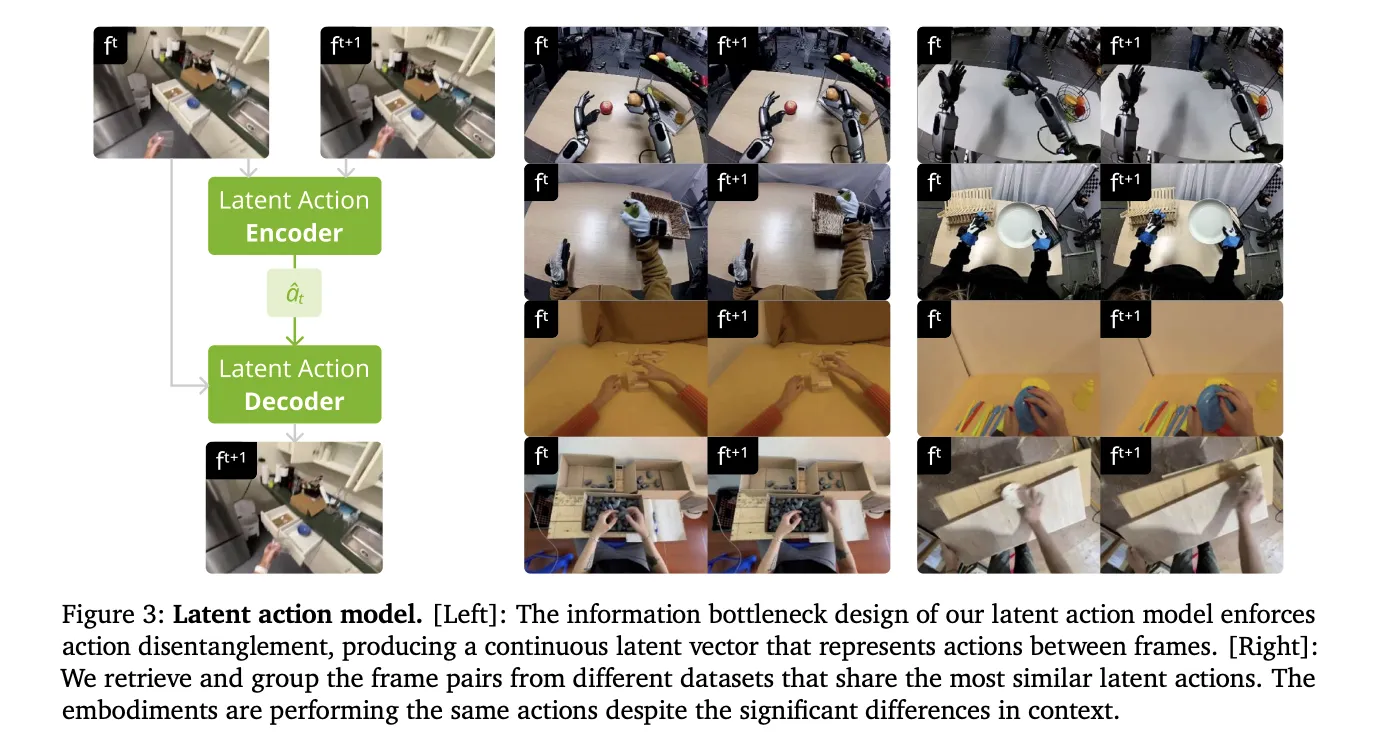
Human videos do not have instructions for robot cars. To make these videos ‘readable like a robot,’ was introduced by the NVIDIA research team subtle ongoing actions. This program uses the Spatiotemporal Transformer VAE to extract actions directly from the pixels.
- The VAE encoder takes 2 consecutive frames and outputs a 32-dimensional hidden vector.
- This vector represents the most important movement between frames.
- The design creates an information bottleneck that separates the action from the visual context.
- This allows the model to learn physics from humans and apply it to different robot bodies.
Better Physics with Architecture
DreamDojo is based on Cosmos-Predict2.5 hidden video distribution model. It uses the WAN2.2 tokenizerwith a transient pressure ratio of 4. The team developed the design with 3 key features:
- Related Actions: The model uses joint deltas instead of absolute positions. This makes it easy for the model to generalize to different trajectories.
- Chunked Action Injection: Injects 4 consecutive actions into each hidden frame. This aligns actions with the tokenizer’s compression ratio and corrects causality confusion.
- Temporary Loss of Consistency: The new loss function matches the predicted frame rate in ground truth transitions. This reduces visual artifacts and keeps objects physically consistent.
Distillation of 10.81 FPS Real-Time Interaction
A simulator is only useful if it is fast. Conventional diffusion models require too many denoising steps to be implemented in real time. The NVIDIA team used a Force yourself distillation pipe to solve this.
- Distillation training is carried out 64 NVIDIA H100 GPUs.
- The ‘student’ model reduces denoising from 35 steps down to 4 steps.
- The final model achieves a real-time speed of 10.81 FPS.
- It is stable for continuous release of 60 seconds (600 frames).
Opens the apps that drop down
DreamDojo’s speed and accuracy power several advanced applications for AI developers.
1. Reliable Policy Evaluation
Testing robots in the real world is risky. DreamDojo works as a high-fidelity simulation simulator.
- Its simulated success rates show a Pearson correlation of (Pearson 𝑟=0.995) with real world results.
- Mean Maximum Violation (MMRV) only 0.003.
2. Model-Based Programming
Robots can use DreamDojo to ‘look ahead.’ A robot can simulate many action sequences and choose the best one.
- In fruit packing work, this has improved real-world success rates by 17%.
- Compared to random sampling, it gave a 2x increase in success.
3. Live Teleoperation
Developers can use virtual robots in real time. The NVIDIA team demonstrated this using ia PICO VR controller and a local desktop with NVIDIA RTX 5090. This allows for safe and fast data collection.
Summary of Model Performance
| Metric | DREAMDOJO-2B | DREAMDOJO-14B |
| The Righteousness of Physics | 62.50% | 73.50% |
| Next Action | 63.45% | 72.55% |
| FPS (Distilled) | 10.81 | N/A |
NVIDIA released all weights, training code, and test benchmarks. This open source release allows you to ship DreamDojo with your robot data today.
Key Takeaways
- Large Scale and Diversity: DreamDojo is pre-trained DreamDojo-HVthe largest database of selfish human videos to date, it has 44,711 hours of pictures on the other side 6,015 unique jobs again 9,869 scenes.
- Combined Latent Action Agent: To overcome the lack of action labels in human videos, the model uses subtle ongoing actions released with Spatiotemporal Transformer VAE, which acts as a hardware-agnostic control interface.
- Advanced Training and Construction: The model achieves high-fidelity physics and precise control through relative action changes, truncated verb injectionand special temporary loss of consistency.
- Real-Time Performance with Distillation: With Force yourself distillation pipe, the model is accelerated 10.81 FPSenabling interactive applications such as live telework and stable, long-horizon simulations 1 minute.
- It’s Reliable for Downhill Operations: DreamDojo works as an accurate simulator of policy evaluationshowing a 0.995 Pearson correlation with real-world success rates, and can improve real-world performance by 17% if used model-based programming.
Check it out Paper again Codes. Also, feel free to follow us Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.




