Alibaba Qwen Group Releases Qwen 3.5 Medium Model Series: A Production Powerhouse That Proves Small AI Models Are Intelligent

The development of large linguistic models (LLMs) has been described in pursuit of a crude scale. While the multi-billion-dollar parameter increase initially led to operational gains, it also introduced significant infrastructure and cost reductions. The release of Qwen 3.5 Medium Model Series it reflects a change in approach for Alibaba’s Qwen, which prioritizes building efficiency and high-quality data over standard measurement.
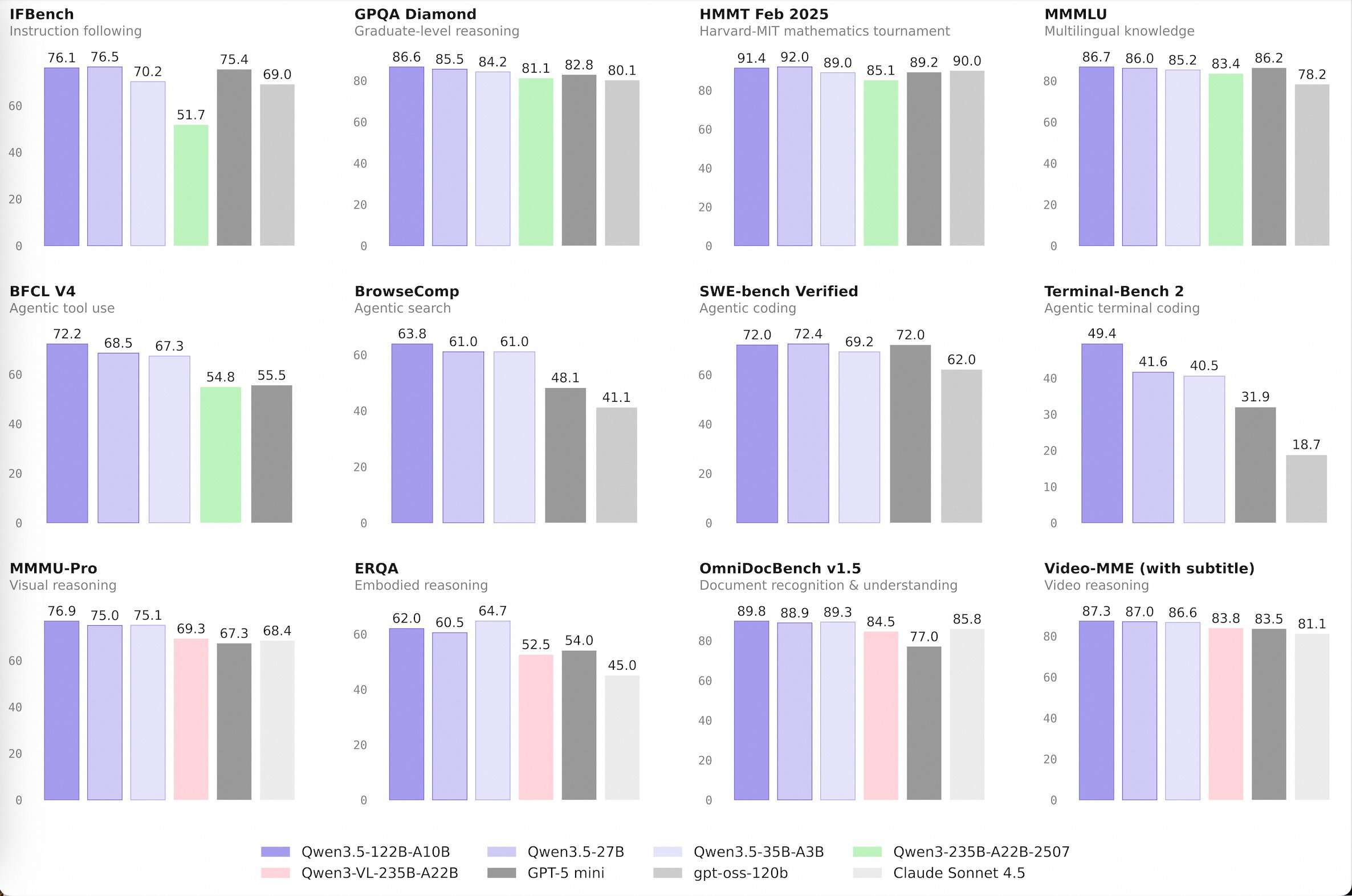
The series contains a list that includes Qwen3.5-Flash, Qwen3.5-35B-A3B, Qwen3.5-122B-A10Bagain Qwen3.5-27B. These models show that a choice of architecture strategy and Reinforcement Learning (RL) can achieve borderline intelligence with very low computational requirements.
Successful Achievement: 35B Over 235B
The most notable technological milestone is the performance of Qwen3.5-35B-A3Bnow he is older than the old one Qwen3-235B-A22B-2507 and those with the ability to see Qwen3-VL-235B-A22B.
The suffix ‘A3B’ is a key metric. This shows the Active parameters in the Mixture-of-Experts (MoE) structure. Although the model has a total of 35 billion parameters, it activates only 3 billion during any one inference pass. The fact that a model with 3B functional parameters can outperform its predecessor with 22B functional parameters highlights a significant jump in computational density.
This efficiency is driven by an integrated hybrid architecture Gated Delta Networks (directed attention) with typical blocks of gated attention. This design allows for high-throughput recording and reduced memory, making high-performance AI accessible on standard hardware.
Qwen3.5-Flash: Optimized for Production
Qwen3.5-Flash it serves as an assumed production version of the 35B-A3B model. It is specially designed for software devs who need low latency performance in agent workflows.
- 1M Core Length: By automatically providing a 1 million token context window, Flash reduces the need for complex RAG (Retrieval-Generation-Advanced) pipelines when handling large document sets or code bases.
- Official Built-in Tools: The model includes native support for tooling and callbacks, allowing it to interact directly with APIs and databases with high precision.
Agenttic Conditions Showing Superiority
I Qwen3.5-122B-A10B again Qwen3.5-27B models are designed for ‘agent’ tasks—situations where the model must plan, reason, and execute multi-step workflows. These models bridge the gap between open-weight variables and proprietary boundary models.
The Alibaba Qwen team used a four-stage pipeline after training on these models, including a chain-of-thought (CoT) cold start and reasoning-based RL. This allows the 122B-A10B model, which uses only 10 billion active parameters, to maintain reasonable consistency in long-horizon operations, which opposes the performance of more dense models.
Key Takeaways
- Architectural Efficiency (MoE): I Qwen3.5-35B-A3B model, with 3 billion active parameters (A3B), outperforms the previous generation model 235B. This shows that Mixture-of-Experts (MoE) architectures, when combined with high data quality and Reinforcement Learning (RL), can deliver ‘borderline’ intelligence at a fraction of the computational cost.
- Production Ready Performance (Flash): Qwen3.5-Flash it is a hosted production model aligned with the 35B model. It is specially optimized for high-end, low-latency applications, making it the ‘workhorse’ for developers moving from prototype to enterprise-level deployment.
- Main Content Window: This series consists of a 1M context length by default. This enables long-term context operations such as full archive code analysis or large document retrieval without the need for RAG (Retrieval-Augmented Generation) ‘processing’ techniques, which simplifies the developer’s workflow.
- Native Tool Usage and Agent Capabilities: Unlike models that require rapid engineering of external interfaces, Qwen 3.5 integrates built-in legal tools. This native support for function calls and API interactions makes it very useful in ‘agent’ scenarios where the model has to plan and execute multi-step workflows.
- The ‘Middle’ Sweet Spot: Focusing on models ranging from 27B to 122B (A10B is active)Alibaba has targeted a ‘Goldilocks’ industry environment. These models are small enough to run on private or localized cloud infrastructures while maintaining the complexity and logical consistency typically reserved for large, closed-source proprietary models.
Check it out Model weights again Flash API. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.




