Google AI Releases WAXAL: A Multilingual African Speech Dataset for Training Automatic Speech Recognition and Transform-to-Speech Examples

Speech technology still has a problem with data distribution. Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems have developed rapidly in widely used languages, but many African languages remain poorly represented in the open source community. A team of researchers from Google and other partners present WAXALan open multilingual speech dataset for African languages covering 24 languages, with an ASR component composed of recorded natural speech and a TTS component composed of studio-quality recordings of a single speaker.
WAXAL is organized as two separate services because ASR and TTS have different data requirements. I Part of ASR it is designed around different speakers, natural environment, and automatic language generation. I Part of TTS designed for controlled recording conditions, phonetically balanced texts, and clean single-speaker sound that’s perfect for mixing. That distinction is technically important: a dataset that is useful for robust recognition in noisy real-world settings is often not the same dataset that generates robust single-speaker TTS models.
How ASR data is collected
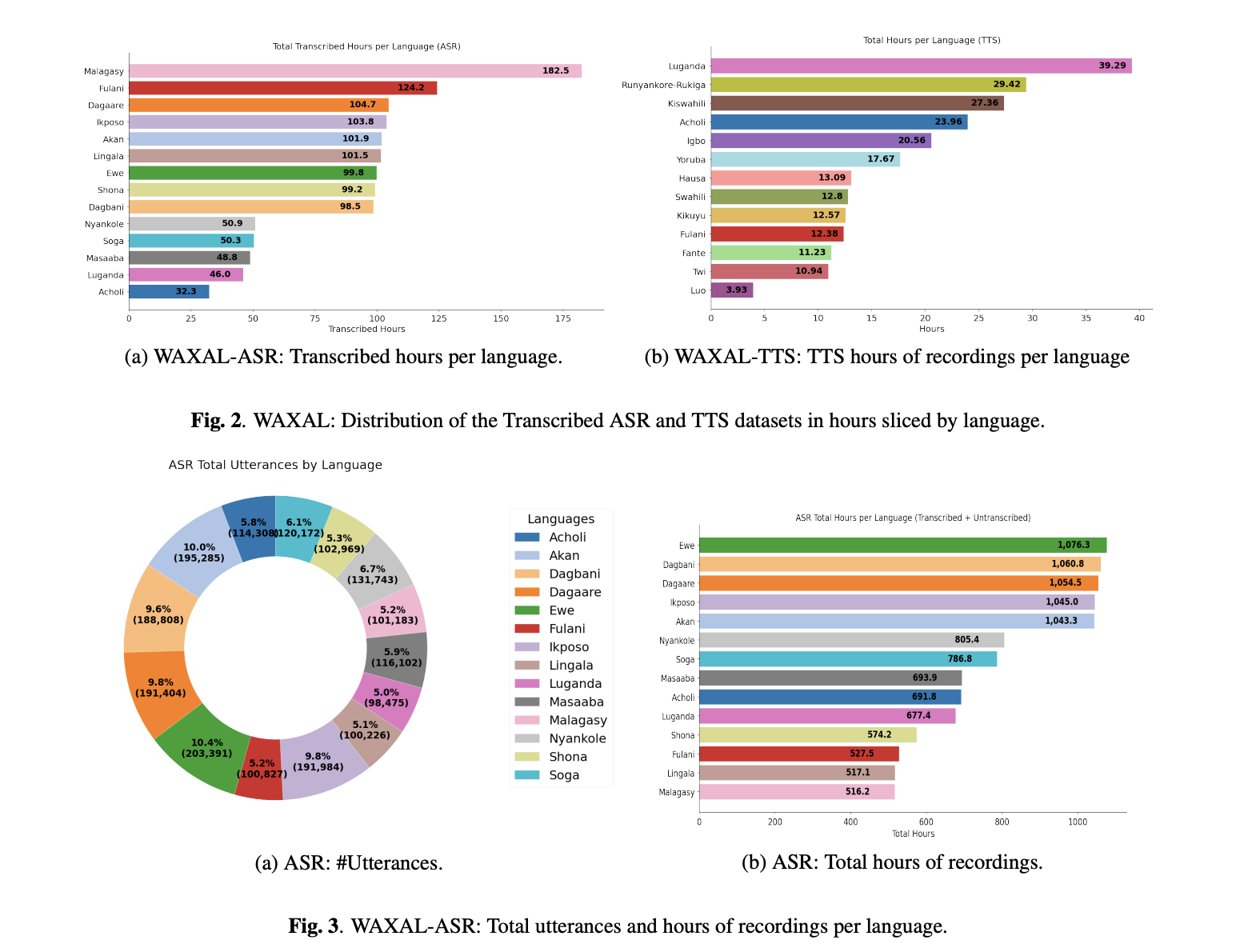
The ASR component of WAXAL was collected using photo-activated speech. Speakers were shown pictures and asked to describe what they saw in their native language, which is a more natural setting than simply reading information. Recordings were taken from the speakers’ natural locations, each with a minimum duration of 15 seconds. The collection process also tracked metadata such as the speaker’s age, gender, language, and recording location. Only a subset of the total collected audio was recorded: the research team says that the current release of ASR includes transcriptions of about 10% of the total recorded audio. Those transcripts were produced by paid local linguists, using local scripts where available and alternative translations of English characters.
This is important for anyone building multilingual ASR programs. Image-stimulated speech tends to capture more natural lexical and syntactic variation than strictly written reading, but it also complicates transcription and increases variation across speakers, backgrounds, and acoustic conditions. WAXAL relies on that trade-off rather than avoiding it. The result is not a completely clean benchmark data set; it’s close to multilingual ASR data collected in the field with real diversity baked into it.
How TTS data is collected
The TTS side of WAXAL is structured very differently. The TTS dataset is designed for high-quality, synthetic speech from a single speaker. For each target language, the research team created a balanced phonetic text of approximately 108,500 words. They contracted with 72 community participants, split equally between male and female voice actors, and recorded them in professional studio-like environments to reduce background noise and maintain audio fidelity. The target was about 16 hours of clean edited audio per voice actor.
This is a good design choice for integration. TTS models are more concerned with consistency in pronunciation, recording conditions, microphone quality, and speaker identity than ASR systems. WAXAL therefore avoids the common mistake of treating ‘speech data’ as a single category, when in practice the ASR and TTS pipelines require very different guard signals.
Key Takeaways
- WAXAL is an open multilingual speech corpus built for low-cost African language ASR and TTS resources.
- ASR data uses image-stimulated natural speech, collected from real-world environments.
- TTS data uses studio-quality, single-speaker recordings with phonetically balanced texts.
Check it out Paper again Data set here. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.

Michal Sutter is a data science expert with a Master of Science in Data Science from the University of Padova. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at turning complex data sets into actionable insights.



