Chroma Releases Context-1: A 20B Agentic Search Model for Multi-Hop Retrieval, Content Management, and Predictive Generation of Tasks

In the current state of AI, the ‘content window’ has become a blunt instrument. We were told that if we just expand the memory of the boundary model, the retrieval problem disappears. But as any AI experts building RAG (Retrieval-Augmented Generation) programs know, cramming a million tokens quickly often leads to high latency, astronomical costs, and ‘lost in the middle’ reasoning failures that no amount of computing seems to fully solve.
Chroma, the company behind the popular open-source vector database, takes a different, more surgical approach. Let them go Context-120B parameter search model designed to function as a small retrieval subagent.
Rather than trying to be a general purpose logic engine, Context-1 is a highly developed ‘scout’. It’s designed to do one thing: find the right supporting documents for complex, multi-hop queries and pass them to the lower bound model to get the final answer.
The rise of the Agentic Subagent
Context-1 is taken from gpt-oss-20BMixture of Experts (MoE) structures Chroma fine-tuned using a combination of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) with CISPO (staged curriculum optimization).
The goal is not just to retrieve the pieces; is to do a sequential thinking activity. When the user asks a complex question, Context-1 doesn’t just hit the vector index once. It decomposes a high-level query into target subqueries, makes corresponding tool calls (average of 2.56 calls per turn), and searches the corpus iteratively.
For AI experts, the architecture change here is the most important thing you take: Narrowing the search to Generation. With the traditional RAG route, the developer handles the retrieval concept. With Content-1, that responsibility is shifted to the model itself. It works within an agent-specific harness that allows it to interact with similar tools search_corpus (hybrid BM25 + dense search), grep_corpus (regex), and read_document.
The Killing Factor: The Context of Self-Organization
The most important innovation in Context-1 is Context of Self-Organization.
As the agent collects information through multiple exchanges, its content window fills up with documents—many of which are simply invalid or inconsistent with the final response. Standard models end up ‘choking’ on this noise. Context 1, however, is trained with pruning accuracy of 0.94.
During the search, the model updates its collected context and continuously uses a prune_chunks command to discard non-essential episodes. This ‘soft pruning’ keeps the context window dependent, freeing up the capacity for deep exploration and preventing the ‘content rot’ that plagues long reasoning chains. This allows the special 20B model to maintain high acquisition quality within the bounded context of 32k, even when navigating datasets that may require very large windows.
Creating a ‘Leak-Proof Benchmark’: context-1-data-gen
To train and test a model in multi-hop reasoning, you need data where the ‘ground truth’ is known and requires multiple steps to access. Chroma has open sourced the tool they used to solve this: context-1-data-gen cache.
The pipeline avoids the pitfalls of static benchmarks by generating multi-hop operations across four specific domains:
- Web: Multi-step research activities from the open web.
- SEC: Financial transactions including SEC filings (10-K, 20-F).
- Copyrights: Legal services focused on USPTO prior art searches.
- Email: Search for works using the Epstein files and the Enron corpus.
Data generation follows strictness Check → Verify → Upload → Indicator pattern. It generates ‘clues’ and ‘questions’ to which the answer can only be found by combining information from multiple documents. By digging up ‘header bugs’—texts that look relevant but have no logical utility—Chroma ensures that the model can’t ‘see’ its way to the right answer through simple keyword matching.
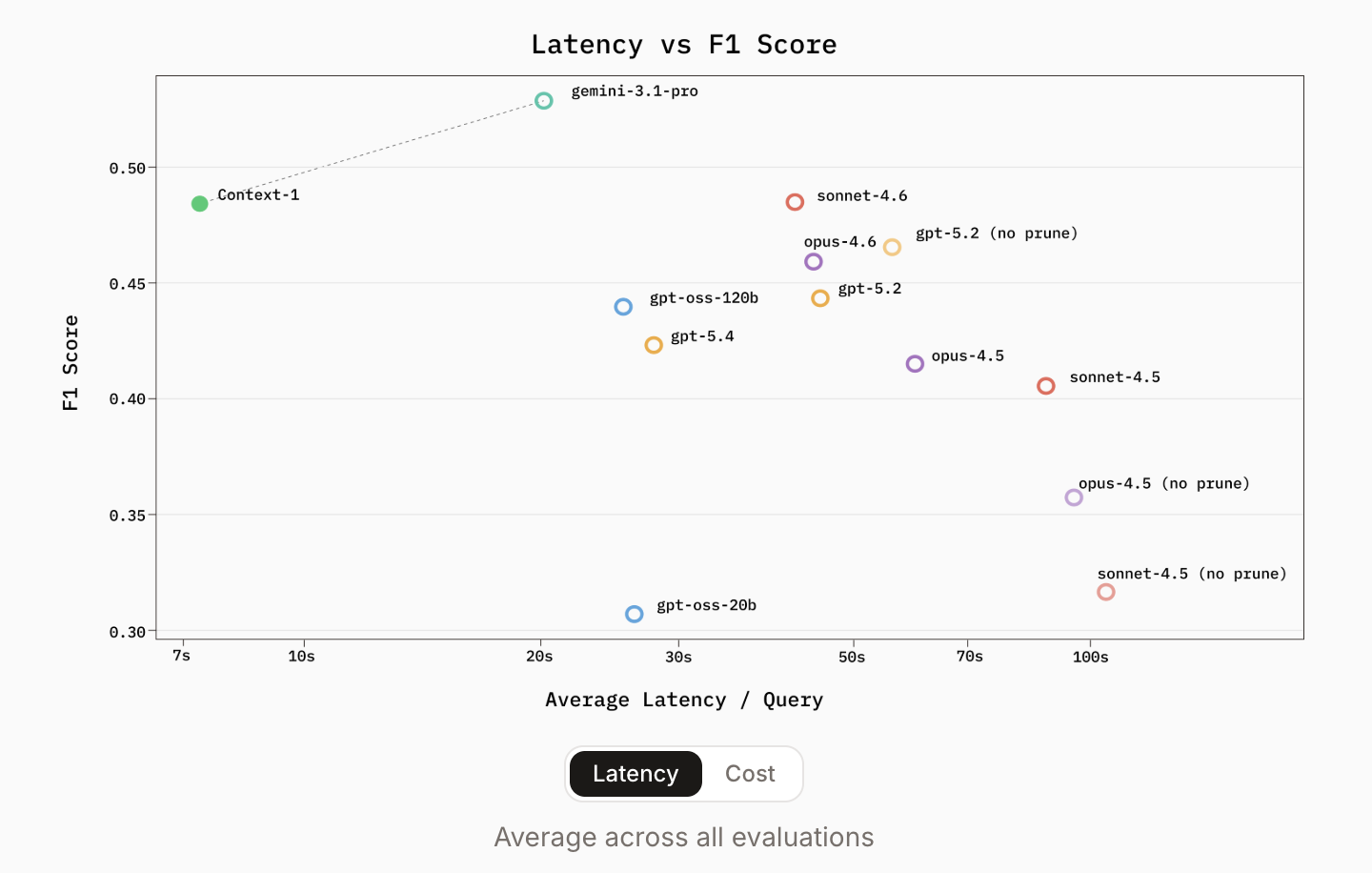
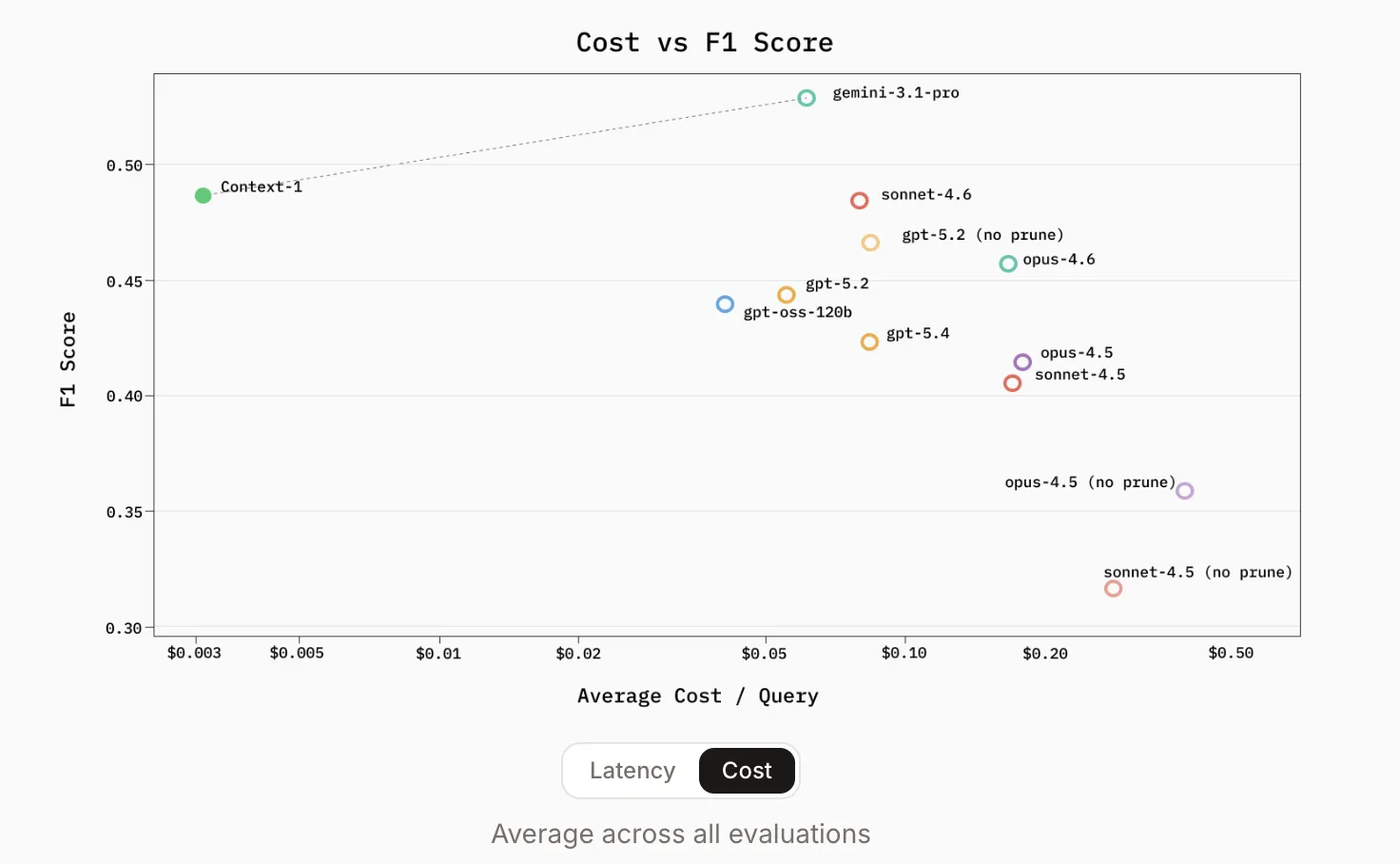
Performance: Fast, Cheap, and Competitive with GPT-5
The benchmark results released by Chroma are a real test of the ‘borderline only’ crowd. Context-1 was tested against heavy metals of the 2026 era including gpt-oss-120b, gpt-5.2, gpt-5.4once Sonnet/Opus 4.5 and 4.6 families.
All public benchmarks are the same Browse Comp-Plus, SealQA, FRAMESagain HotpotQAContext-1 demonstrated retrieval performance comparable to frontier models by orders of magnitude.
The most compelling metrics for AI devs are efficiency gains:
- Speed: Context-1 provides up to 10x faster prediction There are general purpose parameter models.
- Cost: Almost 25x cheaper to work on similar acquisition tasks.
- Pareto Frontier: By using the ‘4x’ configuration—using four agents of Content-1 in parallel and combining the results by combining equal levels—it matches the accuracy of a single operation of GPT-5.4 in the calculation part.
The identified ‘operating cliff’ is not just the length of the token; it’s about hop-count. As the number of reasoning steps increases, conventional models often fail to support the search path. Context-1’s special training allows it to navigate these deep chains more reliably because it is not interrupted by the ‘response’ function until the search is complete.
Key Takeaways
- ‘Scout’ Model Strategy: Context-1 is a 20B special parameter search model (found in gpt-oss-20B) designed to work as a small subagent, proving that a soft, special model can outperform general-purpose LLMs in multi-hop search.
- Self-organization context: To solve the problem of ‘content decay,’ the model introduces a pruning accuracy of 0.94, which allows it to discard irrelevant documents during the search to keep the context window focused and with high signal.
- Leak-Proof Benchmarking: Open sources
context-1-data-genThe tool uses an automated ‘Check → Validate → Raise’ pipeline to create multi-hop operations on web, SEC, Patent, and email databases, ensuring that models are tested on logic instead of memorized data. - Delayed Operation: By focusing only on retrieval, Context-1 achieves 10x faster index and 25x lower cost than frontier models such as GPT-5.4, while matching its accuracy in complex benchmarks such as HotpotQA and FRAMES.
- Tiered RAG Future: This release overcomes the hierarchical architecture where the high-speed subagent selects the ‘golden core’ of the downstream boundary model, effectively solving the latency and failure of large, unmanaged windows.
Check it out Repo again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



