YuanLab AI Releases Yuan 3.0 Ultra: Flagship Multimodal MoE Foundation Model, Built for Strong Intelligence and Unparalleled Efficiency

How can a trillion-parameter Large Language Model achieve high business performance while simultaneously reducing its total parameter value by 33.3% and increasing pre-training efficiency by 49%? Yuan Lab AI releases Yuan3.0 Ultra, an open source Mixture-of-Experts (MoE) language model that includes A total of 1 parameters again 68.8B open parameters. The architecture model is designed to improve efficiency in business-specific operations while maintaining competitive capabilities and common purpose. Unlike traditional compact models, Yuan3.0 Ultra uses minimal to scale capacity without a linear increase in computing costs.
Layer-Adaptive Expert Pruning (LAEP)
The fundamental innovation in Yuan3.0 Ultra training is Layer-Adaptive Expert Pruning (LAEP) algorithm. While professional pruning is usually implemented after training, LAEP identifies and removes unused professionals directly during training. pre-training phase.
Research on the distribution of professional workload reveals two distinct phases during pre-training:
- The first stage of change: It is characterized by high variability in professional loads inherited from unplanned startups.
- Stable Phase: Expert loads converge, and the relative level of experts based on token sharing remains unchanged.
Once the stable phase is reached, LAEP uses castration based on two principles:
- Individual Burden (⍺): Targeted are experts whose token load is much lower than the average layer.
- Cumulative Load Limit (β): It identifies a small group of experts who contribute little to token processing.
Using LAEP with β=0.1 and variance ⍺, the model was trimmed from the original 1.5T parameters down to 1T parameters. This A reduction of 33.3%. in general parameters that preserve the multi-domain performance of the model while significantly reducing the memory requirements for implementation. In the 1T configuration, the number of experts per layer has been reduced from 64 to higher 48 experts retained.
Hardware optimization and expert reconfiguration
MoE models often suffer from device-level load imbalance when experts are distributed across a computing cluster. To deal with this, Yuan3.0 Ultra uses i Expert reprogramming algorithm.
This algorithm balances experts by token load and uses a greedy strategy to distribute it across GPUs so that cumulative token variance is minimized..
| The way | TFLOPS per GPU |
| Base Model (1515B) | 62.14 |
| Loss of DeepSeek-V3 Aux | 80.82 |
| Yuan3.0 Ultra (LAEP) | 92.60 |
Pre-training overall efficiency was improved by 49%. This improvement is due to two factors:
- Pruning Model: Offered 32.4% in achieving efficiency.
- Professional reordering: Offered 15.9% in achieving efficiency.
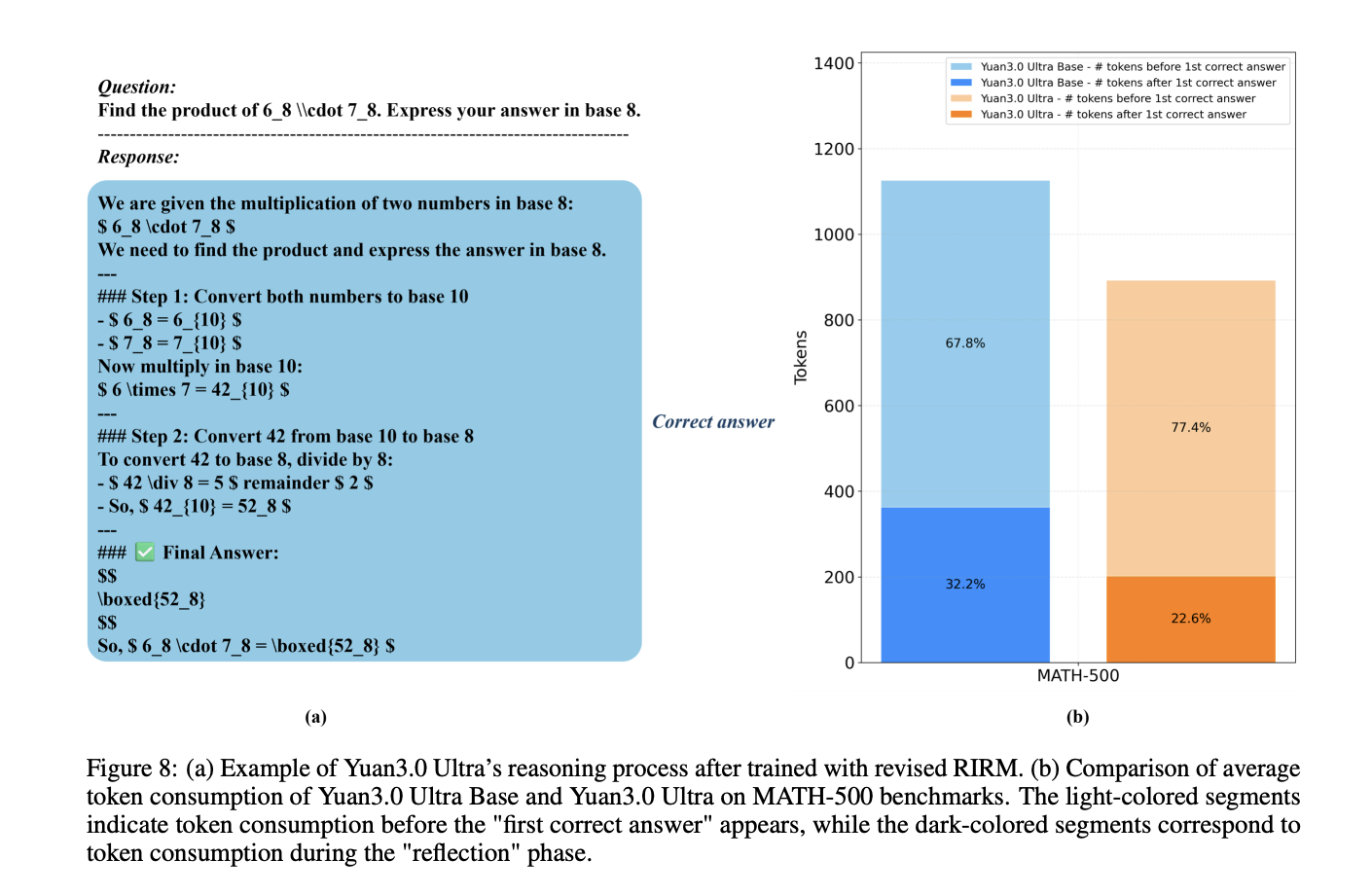
Reducing Overthinking with the Revised RIRM
In the reinforcement learning (RL) phase, the model uses refined Reflection Inhibition Reward Mechanism (RIRM) preventing overly long thought chains to perform simple tasks.
The reflection reward, $R_{ver}$, is calculated using a boundary-based penalty system:
- rmin=0: Reasonable number of thinking steps for direct answers.
- rplural=3: The most tolerable display limit.
For correct samples, the reward decreases as the display steps approach rpluralwhile negative samples ‘overthink’ (exceed urplural get high fines. This process led to a 16.33% gains in training accuracy and a 14.38% reduction in output token length.

Business Benchmark Performance
The Yuan3.0 Ultra was tested against several industry models, including the GPT-5.2 and Gemini 3.1 Pro, in all business-specific benchmarks..
| Benchmark | Work class | Yuan3.0 Ultra Score | Best Competitor Score |
| Docmatix | Multimodal RAG | 67.4% | 48.4% (GPT-5.2) |
| ChatRAG | Text Retrieval (Avg) | 68.2% | 53.6% (Kimi K2.5) |
| MMTab | Table Consultation | 62.3% | 66.2% (Kimi K2.5) |
| SummEval | Text Summary | 62.8% | 49.9% (Claude Opus 4.6) |
| Spider 1.0 | Text-to-SQL | 83.9% | 82.7% (For me K2.5) |
| BFCL V3 | Persuasion Tool | 67.8% | 78.8% (Gemini 3.1 Pro) |
The results show that Yuan3.0 Ultra achieves state-of-the-art accuracy in multi-item retrieval (Docmatix) and long-range content retrieval (ChatRAG) while maintaining strong performance in structured data processing and tool typing..
Check out Paper again Repo. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



