NVIDIA AI Releases Nemotron-Terminal: A Systematic Data Engineering Pipeline for Measuring LLM Terminal Agents

The race to build autonomous AI agents has hit a major bottleneck: data. While benchmark models like Claude Code and Codex CLI have shown impressive expertise in endpoints, the training techniques and data mixes behind them remain closely guarded secrets. This lack of privacy has forced researchers and devs into an expensive cycle of trial and error.
NVIDIA is now breaking that silence by unveiling a complete framework for building high-performance agents. By introduction Terminal-Work-Gen as well as Terminal-Corpus dataset, NVIDIA is essentially giving the engineering community blueprints for building agents that don’t just ‘talk’ about code, but actually do it with surgical precision.
The Problem of Missing Data
The challenge of training a command line agent is twofold. First, there is a lack of basic resources—in particular, the various information functions and complex dependency files needed to create virtual environments. Second, capturing ‘trajectories’ (step-by-step terminal interactions) is a pain in the ass. Human interactions are faster to record, and production of LLM agents is prohibitively expensive because it requires a new Docker environment startup for each turn.
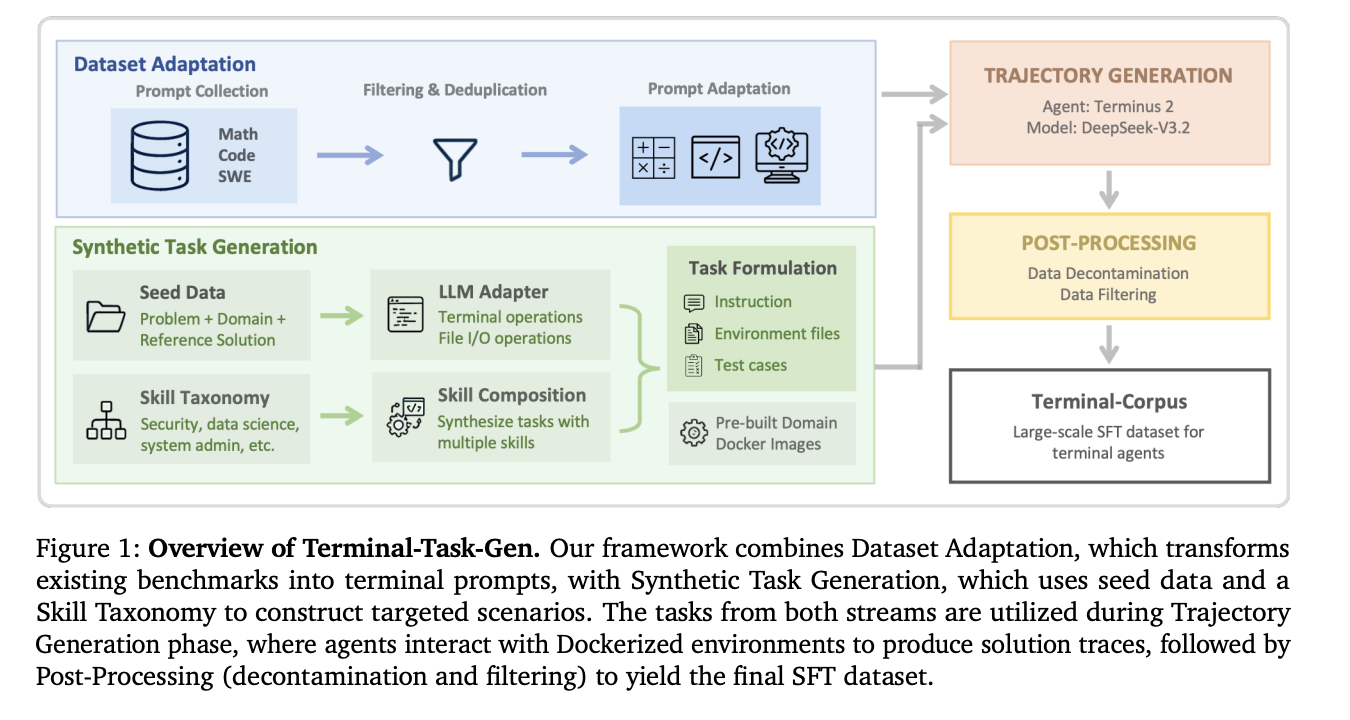
Terminal-Task-Gen: A Two-Pronged Strategy
NVIDIA’s solution is a so-called ‘coarse-to-fine’ data generation pipeline Terminal-Work-Gen. It uses two different techniques to scale training data without breaking the bank.
1. Normalization of the data set (Coarse Layer)
Instead of starting from scratch, the team uses existing high-quality datasets for Supervised Fine-Tuning (SFT) from the domains of mathematics, coding, and software engineering (SWE).. They convert these static instructions into interactive terminal functions.
- Math and code: Using 163K statistical data and 35K code data, they wrapped these challenges into the final scaffold.
- WE: They pull 32K different commands from repositories like SWE-bench and SWE-reBench. The clever part? This process does not require LLM “in the loop” to adapt, making it incredibly efficient to measure volume.
2. Synthetic Task Generation (Fine Layer)
To bridge the gap between conventional thinking and the specific complexity of the end agency, the NVIDIA team uses Terminal-Work-Gen to create novel, usable functions.
- Seed-based generation: The LLM uses existing scientific computer or algorithmic problems as “inspiration” to synthesize new tasks. The agent is forced to install packages, read input files, and write output—replicating the workflow of a real-world developer.
- Skill-based generation: This is where it gets technical. NVIDIA has chosen to tax “classical storage capabilities” across nine domains, including Security, Data Science, and Systems Management. The LLM is then instructed to combine 3–5 of these starting points (such as graph traversal + network configuration + file I/O) into a single, complex task.
High Resolution Infrastructure
One of the most important achievements of engineering in this study is to move to Pre-built Docker Images. Previous frameworks used to generate a unique Dockerfile for every single task, leading to huge build time delays and frequent failures. The NVIDIA team instead maintains nine preconfigured shared images with important libraries (such as pandas for data science or encryption tools for security). This ‘one pass’ fabrication method allows for greater uniformity and a much smaller tool footprint.
Operation: When 32B Hits 480B
The results of this data-centric approach are amazing. The NVIDIA team used this pipeline for training Nemotron-Terminal family of models, started at Qwen3.
You have Terminal-Bench 2.0 benchmark, which tests agents in end-to-end workflows such as training machine learning models or debugging system environments, development was straightforward:
- Nemotron-Terminal-8B: It increased from 2.5% success to 13.0%.
- Nemotron-Terminal-32B: Achieved a 27.4% accuracy.
To put that in perspective, the 32B model is very successful 480B Qwen3-Coder (23.9%) and competed with the performance of closed giants such as Episode 4 (23.1%) and GPT-5-Mini (24.0%). This proves that for finite agents, high-level, multi-trajectory data is a stronger defense than parameter scaling..
Important Ideas
NVIDIA research also dispels several common myths in data engineering:
- Do not filter Errors: The research team found that keeping ‘failed’ clues in the training data actually improved performance (12.4% vs 5.06% for successful sorting only). Exposing the models to error conditions and recovery patterns makes them more robust.
- Skip the Curriculum: They tried ‘curriculum learning’ (training with simple data before hard data) but found that mixed simple training was just as effective, if not better.
- Content length restrictions: Although terminal trajectories can be long, most high-quality observations fit within a standard window of 32,768 tokens. Extending the context length slightly hurts performance, probably because long-tailed trajectories tend to be noisy.
Check it out Paper again HF Project Page. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



